Transformer
参考文章
-
手把手教你
-
YouTube教学视频
-
LLM可视化网站
介绍
结构
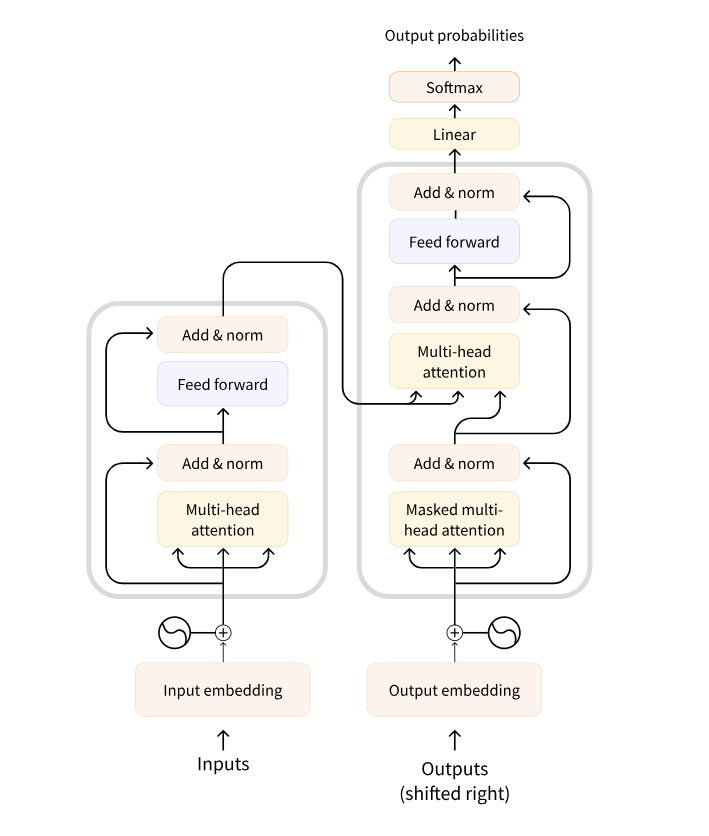
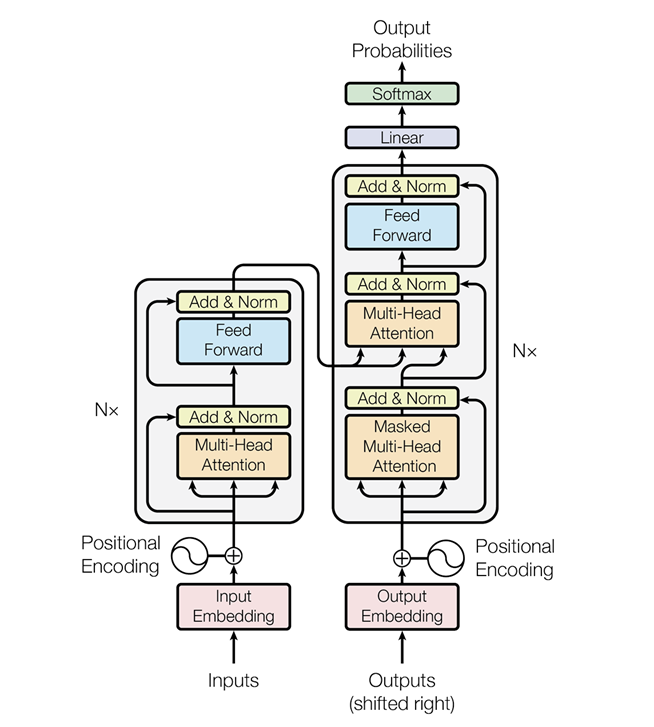
论文的原始结构,此处 N=6
transformer是一篇划时代的论文,大模型力大砖飞的典范
NLP问题划时代的解决方案
模块介绍
词嵌入 (Word Embedding)
实现
"""
将输入的离散词索引转换为连续的向量表示
例如,将词汇表中的第5个词映射为一个512维的向量
"""
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
# 初始化方法,传入模型的维度(d_model)和词汇表的大小(vocab)
super(Embeddings, self).__init__()
# Embedding层,将词汇表的大小映射为d_model维的向量
self.lut = nn.Embedding(vocab, d_model)
# 存储模型的维度 d_model
self.d_model = d_model
def forward(self, x):
# 返回x对应的embedding矩阵(需要乘以math.sqrt(d_model))
# 这是为了保持词向量的方差,使其适应后续层的训练。
return self.lut(x) * math.sqrt(self.d_model)
位置编码 (Positional Encoding)
原版Transfomer使用的为: 正余弦位置编码

目的是将词向量矩阵中加入一些位置信息
$$ \begin{cases} PE(pos, 2i) = \sin!\left(\frac{pos}{10000^{\frac{2i}{d_{\text{d}}}}}\right) \ PE(pos, 2i+1) = \cos!\left(\frac{pos}{10000^{\frac{2i}{d_{\text{d}}}}}\right) \end{cases} \ \text{d:词嵌入矩阵大小} \ i=0,1,…,\frac{d}{2}-1 \space\space pos指当前token在序列中的第几个位置 $$
其目的是将上下文增加位置信息,让模型识别到
最终经过这两层后获取的数据为: $$ encoded\space patches = patch\space embedding + positional\space embedding $$
实现
"""
为每个输入位置添加一个唯一的位置编码
这个编码会被添加到词向量中,使模型能够理解位置信息
"""
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 初始化一个size为 max_len(设定的最大长度)×embedding维度 的全零矩阵
# 来存放所有小于这个长度位置对应的positional embedding
pe = torch.zeros(max_len, d_model, device=DEVICE)
# 生成一个位置下标的tensor矩阵(每一行都是一个位置下标)
position = torch.arange(0., max_len, device=DEVICE).unsqueeze(1)
# 这里幂运算太多,我们使用exp和log来转换实现公式中pos下面要除以的分母(由于是分母,要注意带负号)
div_term = torch.exp(torch.arange(0., d_model, 2, device=DEVICE) * -(math.log(10000.0) / d_model))
# 根据公式,计算各个位置在各embedding维度上的位置纹理值,存放到pe矩阵中
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 加1个维度,使得pe维度变为:1×max_len×embedding维度
# (方便后续与一个batch的句子所有词的embedding批量相加)
pe = pe.unsqueeze(0)
# 将pe矩阵以持久的buffer状态存下(不会作为要训练的参数)
self.register_buffer('pe', pe)
def forward(self, x):
# 将一个batch的句子所有词的embedding与已构建好的positional embeding相加
# (这里按照该批次数据的最大句子长度来取对应需要的那些positional embedding值)
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
自注意力机制 (Self-Attention)
注意力 Attention
$$ \begin{equation} \text{Attention}(Q, K, V) = \mathrm{softmax}!\left(\frac{QK^{\top}}{\sqrt{d_k}}\right)V \end{equation} $$
多头注意力机制 (Multi-Head Attention)
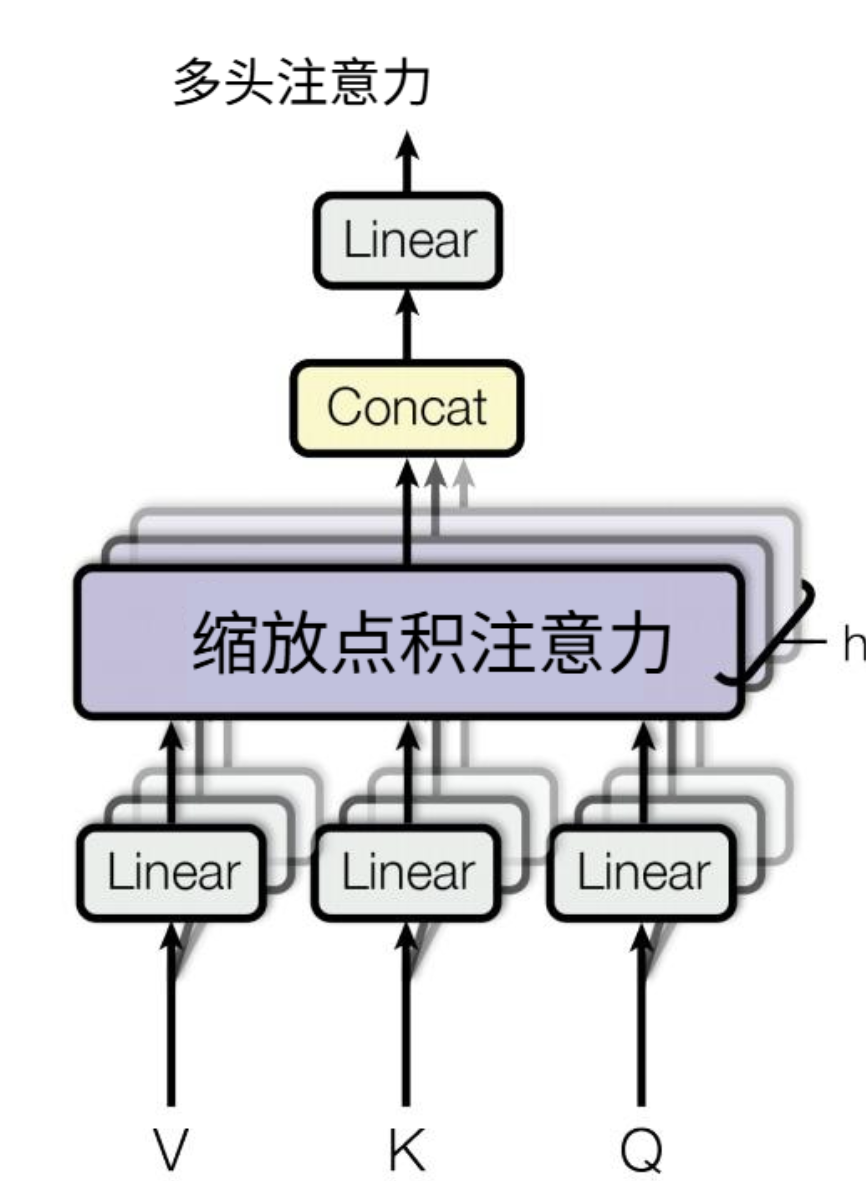
多头注意力机制就是 多个平行的自注意力机制
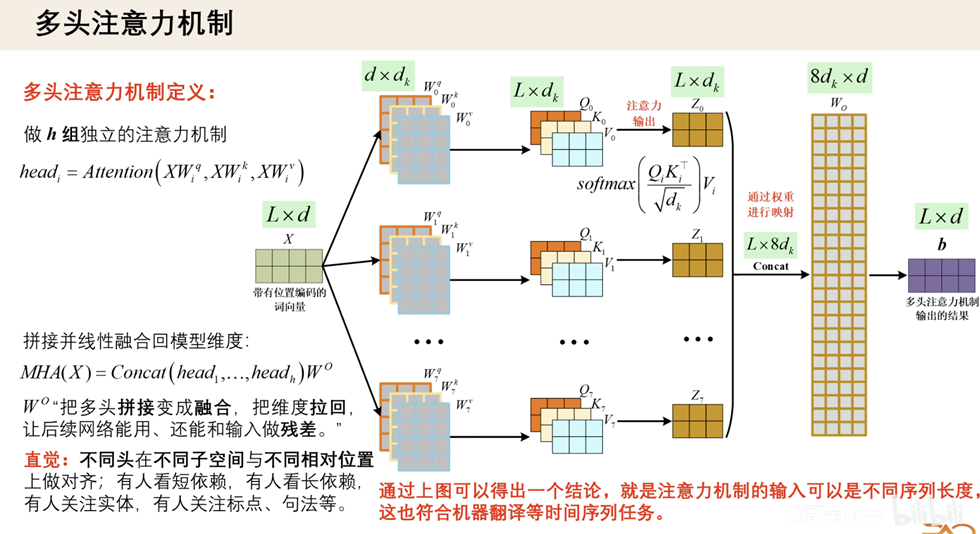
$$ \begin{equation} \text{MultiHead}(Q,K,V) = \mathrm{Concat}(h_1, \ldots, h_h)W^O \end{equation} $$
$$ \begin{equation} h_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) \end{equation} $$
concat 操作
掩码注意力机制 (Masked Self-Attention)
交叉注意力机制 (Cross-Attention)
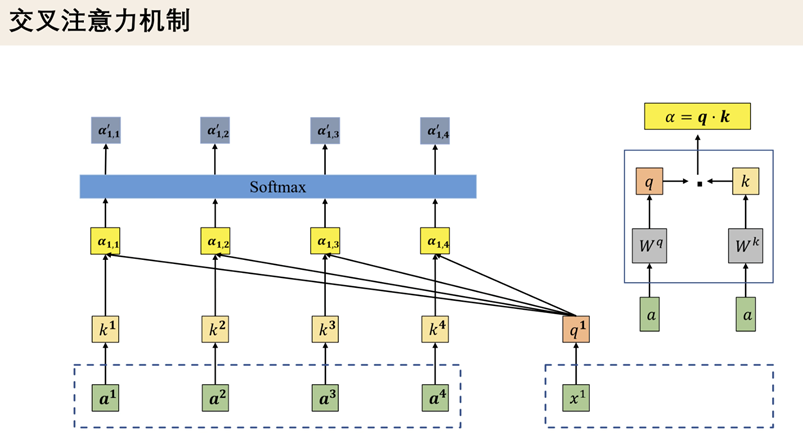
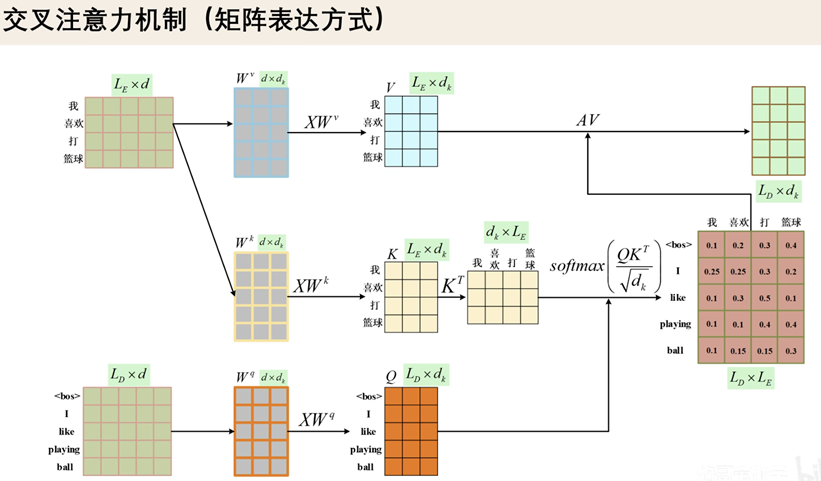
Q,K,V来自不同的结构,
Q,K来自解码器
V来自编码器
层归一化 (Layer Normalization)
归一化操作分成了
- 批归一化 ( Batch Normalization, BN )
- 层归一化 ( Layer Normalization, LN )
| 项目 | 批归一化 BN | 层归一化 LN |
|---|---|---|
| 归一化维度 | 在 batch 维度上做归一化 | 在特征维度(每个样本)上做归一化 |
| 是否依赖 batch size | 是(需要较大 batch 才稳定) | 否(batch size = 1 也行) |
| 训练 / 推理一致性 | 训练与推理行为不同(使用 moving mean/var) | 训练与推理行为完全一致 |
| 主要使用场景 | CNN 卷积网络 | RNN / Transformer / NLP |
| 对序列模型 | 效果不好 | 效果极佳 |
| 是否对通道/特征进行逐样本归一化 | 否 | 是 |
批归一化
层归一化操作
$$ \begin{equation} \mathrm{LayerNorm}(x) = \gamma \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta \end{equation} $$
自归一化 加残差连接 $$ \begin{equation} \mathrm{Output} = \mathrm{LayerNorm}\big(x + \mathrm{Sublayer}(x)\big) \end{equation} $$
总结
| 方法 | 均值 / 方差计算维度 | 归一化公式核心 |
|---|---|---|
| BN | 跨 batch,对每个特征单独做 | $$((x - \mu_\text{batch}) / \sigma_\text{batch})$$ |
| LN | 单个样本内部的所有特征 | $$((x - \mu_\text{layer}) / \sigma_\text{layer})$$ |
从矩阵的角度
变体
位置编码的改进
原版使用的是正余弦位置编码