工欲善其事必先利其器,在深度学习时代下,了解每一种显卡的定位就尤为重要了
我初步将深度学习的nvidia显卡划分成了一下几种
- 训练卡(AI train)
- 推理卡(AI Infer)
- 通用计算卡(HPC)
由于通用计算卡目前的市场需求逐渐变小,云服务商也主要提供AI算力,固不列通用计算卡
一些太老的卡就不统计了,只列目前云服务厂商的服务器还普遍使用的卡,消费级显卡就不列了
nvidia-gpu架构发展
1. Pascal(2016)
架构:Pascal
● 特点:大幅提升 FP32 / FP64,首次引入 NVLink ● 典型卡:
- Tesla P100(HBM2,高性能计算)
- Tesla P40(推理优化)
2. Volta(2017)
架构:Volta
● 特点:首次引入 Tensor Core(FP16 AI加速) ● 典型卡:
- Tesla V100(行业旗舰训练卡)
- Tesla V100S(强化版)
- 推理卡:Tesla T4(Volta Turing 混合时代,低功耗推理王者)
3. Turing(2018)
架构:Turing
● 特点:INT8/INT4 推理增强 ● 典型卡:
- T4(最典型的云推理卡)【原 Tesla T4】
4. Ampere(2020)
架构:Ampere
● 特点:第三代 Tensor Core、TF32、稠密/稀疏加速 ● 典型卡:
⭐训练卡:
- A100(旗舰训练/推理/HPC 三合一)
- A100 PCIe / A100 SXM4
⭐推理卡:
- A10, A30(推理+轻训练)
- A2(低功耗)
5. Hopper(2022)
架构:Hopper
● 特点:Transformer Engine、FP8、超大带宽 NVLink ● 典型卡:
- H100 PCIe / SXM5(AI 旗舰,FP8)
- H100 NVL(双GPU NVLink,Llama/GPT 推理)
6. Ada Lovelace(2023)
架构:Ada
● 特点:更高效能比,专注推理 ● 典型卡:
- L4(云推理主力)
- L40 / L40S(AI 推理 + 渲染)
7. Blackwell(2024-2025)
架构:Blackwell(B100 / B200 / GB200)
● 特点:第2代 Transformer Engine、FP4、AI 超算时代 ● 典型卡:
- B100(AI 训练/推理旗舰)
- B200(性能更强)
- GB200 NVL36 / GB200 NVL72(Grace+Blackwell 超级 GPU 组合)
典型推理卡
现在各大云厂商在 NVIDIA 推理卡 上,大致是这样一条线:
Turing:T4 → Ampere:A10 → Ada:L4/L40(L40S) 其中 A100/H100/H20/H200、B200/GB200 这一类是**“训推一体的大模型卡”**,也大量用于推理。(Qiita)
1)Pascal 架构 —— P4(老牌推理卡,主要在 GCP)
NVIDIA Tesla P4:当年就是为视频和在线推理做的卡(Google Cloud)
| 卡 / 架构 | AWS | Azure | Google Cloud | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|
| P4 (Pascal) | 基本不对外主推(AWS 的 P4d 是 A100,不是 P4)(Amazon Web Services, Inc.) | 官方现在主推 T4/A10/L4/H100 等,新建项目几乎不会再用 P4 | 仍可在 N1+P4 模式挂载使用,用于老系统推理/视频等(Google Cloud Documentation) | 官方 GPU 实例家族文档已不再突出 P4,主推 T4/A10 以及新一代 LLM 实例(AlibabaCloud) | 文档中主推的是 T4/V100/A100/H 系列,未见 P4 新实例(tencentcloud.com) | 现有 shape 文档主要列 A10/A100/L40S 等,新项目不会再选 P4(Oracle Docs) |
P4 为“存量/兼容”,不是新项目推荐。
2)Turing 架构 —— T4(云推理“神卡”)
NVIDIA T4 / Tesla T4:70W、16GB,云上经典推理卡(Amazon Web Services, Inc.)
| 卡 / 架构 | AWS | Azure | Google Cloud | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|
| T4 (Turing) | EC2 G4/G4dn:主打“最低成本推理 + 小规模训练”(Amazon Web Services, Inc.) | NCasT4_v3 系列:最多 4×T4,官方定位实时推理/AI 服务部署(Microsoft Learn) | Compute Engine 支持 T4 GPU,且 G4 系列面向“成本优化的 ML 推理”(Google Cloud Documentation) | vGPU 实例族提供 Tesla T4(可 1/4 / 1/2 切分),用于并发推理和图形业务(AlibabaCloud) | GN7 机型明确使用 Tesla T4(16GB),适合实时推理等高并发任务(tencentcloud.com) | 公开的 shape 主要是 A10/A100/L40S 等;T4 不再是主打产品(Oracle Docs) |
可在表里给 T4 标注:“传统云推理主力(2019–2023),很多厂商仍大量在用”。
3)Ampere 架构 —— A10 为主,A2/A30/A40 辅助
| 卡 / 架构 | AWS | Azure | Google Cloud | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|
| A10 (Ampere) | EC2 G5:最多 8×A10G,官方说适合训练+推理(NLP、CV、推荐等)(Amazon Web Services, Inc.) | NVadsA10_v5:A10 + EPYC Milan,可做 vGPU,适合图形 + 推理场景(Microsoft Learn) | 官方 GPU 列表重点在 A100/H100/T4/L4,A10 比较少被单独突出(更多是历史 G 系列里用过)(Google Cloud Documentation) | gn 系列实例使用 A10,文档点名支持 vGPU、TensorRT 等以承载 AI 推理任务(AlibabaCloud) | 公共文档主推 T4/V100/A100/H 系列,A10 用途相对低调(可以在表中标“可能通过部分 GPU 实例提供”)(tencentcloud.com) | BM.GPU.A10:24GB A10 Tensor Core GPU,适合作为中端推理/渲染卡(Oracle Docs) |
4)Ada 架构 —— L4 / L40 / L40S
这里是新一代推理主力,尤其是 L4。
| 卡 / 架构 | AWS | Azure | Google Cloud | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|
| L4 (Ada) | EC2 G6:最多 8×L4,支持 1/8 卡切分,官方定位“成本优化的 ML 推理与图形”(Amazon Web Services, Inc.) | Azure Learn 目前主要从 vGPU / Azure Local 的角度支持 L4/L40/L40S(公有云主线 VM 还以 A10/T4/H100 等为主)(NVIDIA Docs) | G2 系列:标配 L4,官方写明“面向成本优化的推理、图形和 HPC”,并有博客专门说 G2+L4 是生成式 AI 推理平台(Google Cloud Documentation) | 近期重点在 gn8v 等 LLM 实例(多为 H20/H800 系),L4 尚未像 GCP/AWS 那样高调;可以在表中标“暂无公开标准实例”(AlibabaCloud) | 公共 GPU 规格中目前看不到明确的 L4 机型,主力仍是 T4/V100/A100/H100 等(tencentcloud.com) | 暂无 L4 专门 shape,OCI 在推理方向更强调 L40S/A10/A100/H100 等(Oracle Docs) |
“L4:T4 → A10 之后的新一代通用云推理主力,GCP G2 / AWS G6 是代表。”
L40 / L40S:偏“通用大算力 + 训练 + 推理”
| 卡 / 架构 | AWS | Azure | Google Cloud | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|
| L40 / L40S (Ada) | AWS 目前主推的是 A10/L4/A100/H100,L40/L40S 多见于 on-prem/vGPU 方案 | NVIDIA vGPU 支持 Azure Local 上的 L40/L40S,用于本地集群推理/图形(NVIDIA Docs) | 公有文档暂未突出 L40/L40S,重点仍是 L4/A100/H100(Google Cloud Documentation) | 很多 LLM 训练/推理新闻中提到阿里使用 H20/H800 系 GPU 做 LLM 推理,L40S 在国内云上出现较少(Tom’s Hardware) | 暂无公开大规模 L40S 实例信息 | OCI:BM.GPU.L40S.4,明确用于生成式 AI、LLM 训练与推理(blogs.oracle.com) |
5)用作“大模型推理”的训练卡(A100 / H100 / H20 / H200 / Blackwell)
在实际云上,大模型推理很多直接跑在训练集群卡上。
| 架构 | 卡 | 典型云厂商 & 场景(只写跟推理相关) |
|---|---|---|
| Ampere | A100 | AWS P4d、GCP A2、Azure ND A100 v4、阿里/腾讯/OCI 大量用来做 LLM 训练+推理,MLPerf Inference 中 A100 也是主力之一(Amazon Web Services, Inc.) |
| Hopper | H100 | GCP A3 系列(H100)、Azure ND H100 v5、AWS P5、OCI H100 VM/裸金属,都是 GPT/LLama 类模型训练 & 高吞吐推理平台(Google Cloud) |
| Hopper+HBM | H200 / H20 / H800 | H200 在 AWS/GCP/OCI 被当成“大模型推理优化版 H100”,H20/H800 则大量出现在中国云厂商(如阿里)的大模型推理场景中,用于规避出口限制(Tom’s Hardware) |
| Blackwell | B200 / GB200 / GB300 NVL | Azure 上已经部署了 GB300 NVL72 超级集群,面向大规模 FP4 推理/OpenAI 训练;GCP/OCI 也在公布 GB200/B200 形状,用于下一代 LLM 训推一体集群(Tom’s Hardware) |
“LLM 推理解法:直接使用训练卡集群(A100/H100/H200/B200/GB200/GB300)”
典型训练卡
说明:信息来自各云厂商官方文档(截至 2025-11),不同 Region 供应会有差异。
1)Pascal 架构(Tesla P100)
主要卡:Tesla P100 16GB
| 架构 | 典型训练卡 | AWS | Azure | GCP | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|---|
| Pascal | P100 | 基本不主推(以 V100 起步) | 早期有少量 P40/P100,现核心在 V100/A100 | 提供 P100,可挂在 Compute Engine 上做训练(Google Cloud) | ACK/弹性 GPU 中支持 P100(多用于教学/传统 DL)(AlibabaCloud) | 以 V100/A100/H100 为主,很少再见 P100 | 大量 P100 形态:VM.GPU2 / BM.GPU2 等形状(Oracle Docs) |
用途:现在多是老项目、成本敏感的传统训练,新项目一般不再选 Pascal。
P100 显卡的具体参数:
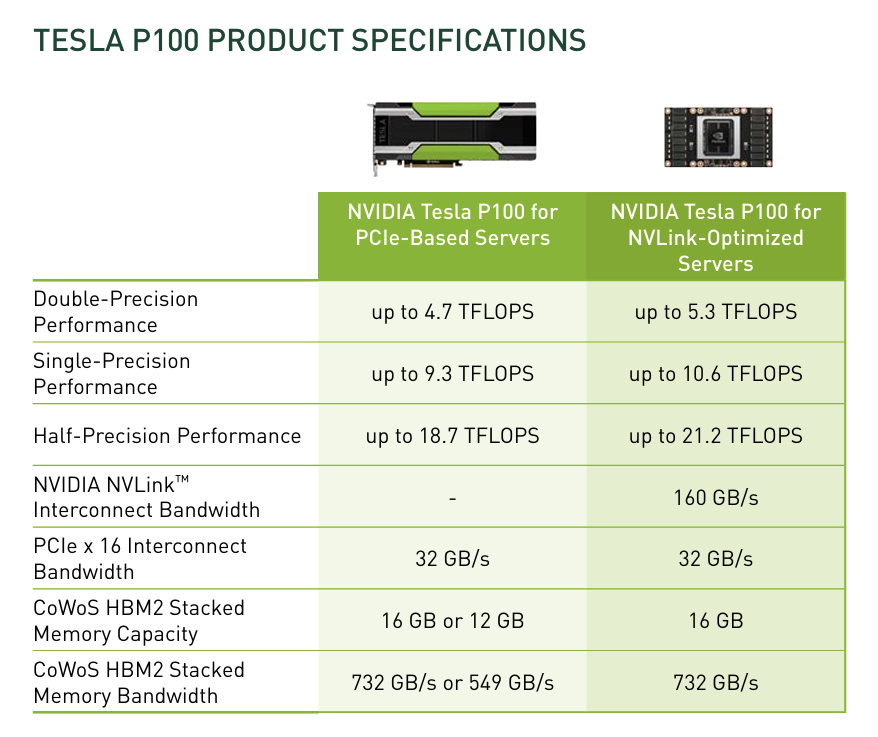
2)Volta 架构(Tesla V100)
主力卡:Tesla V100 16/32GB(曾经的旗舰训练卡)
| 架构 | 典型训练卡 | AWS | Azure | GCP | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|---|
| Volta | V100 | P3 系列:最多 8×V100,官方推荐用于 DL 训练(AWS 文档) | NDv2 / NCsv3 系列:8×V100,面向高端 AI/HPC 训练(Microsoft Learn) | Compute Engine 提供 V100 选项用于训练(Google Cloud) | ACK 集群支持 V100(和 P100/A100 同列)(AlibabaCloud) | GPU Cloud / GN10X 等实例支持 V100 HPC 集群(tencentcloud.com) | VM.GPU3 / BM.GPU3 等形状均为 V100(Oracle Docs) |
用途:目前仍大量用于中等规模模型训练,是许多云上“性价比训练卡”的下限。
V100显卡具体参数:
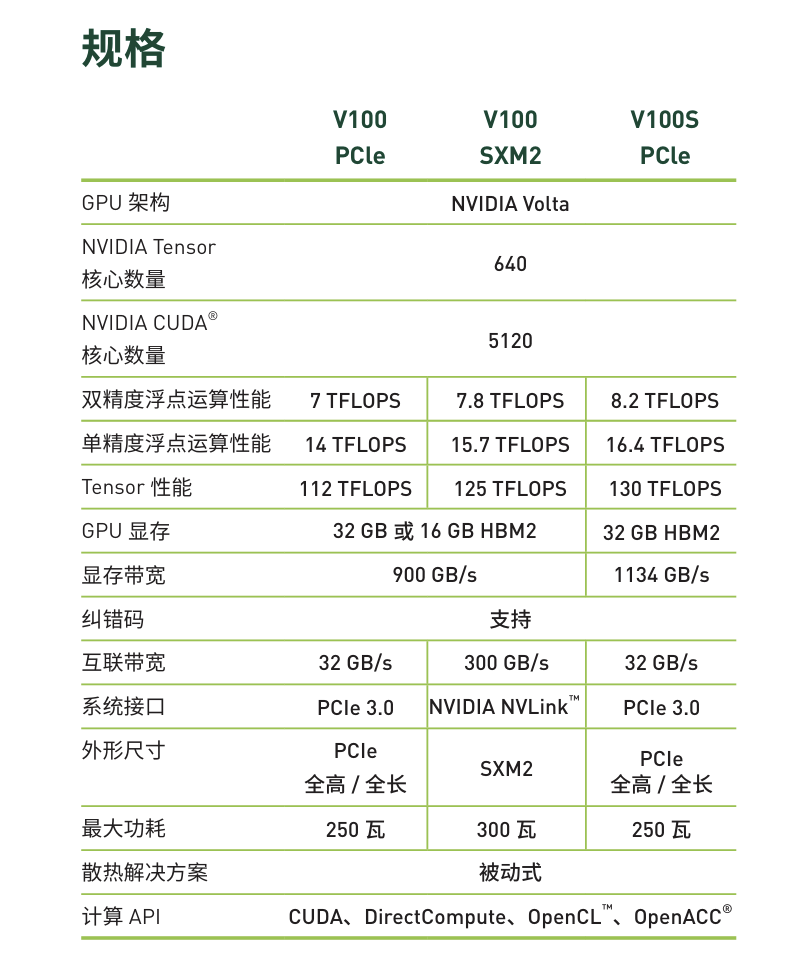
3)Turing 架构(T4 —— 偏推理/轻训)
主力卡(偏推理):Tesla T4 16GB
| 架构 | 典型卡 | AWS | Azure | GCP | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|---|
| Turing | T4 | G4 系列:最多 4×T4,官方定位为推理 GPU(也可小模型训练)(AWS 文档) | NCasT4_v3 系列:1–4×T4,Azure 明确用于 AI 服务、推理工作负载(Microsoft Learn) | Compute Engine 提供 T4(推理 / 轻训 / 视频处理)(Google Cloud) | vGPU/gn 系列中提供 T4(分时/共享 GPU)(AlibabaCloud) | 弹性 GPU / 渲染实例支持 T4、P4 等,用于推理和图形任务(Paperspace by DigitalOcean Blog) | 主要以 P100/V100/A10/A100/H100 为主,T4 较少出现在训练方案中(docs.public.content.oci.oraclecloud.com) |
定位:云推理和轻量训练卡,“推理为主,可用于小模型训练”。
T4的详细参数:

4)Ampere 架构(A100 为主)
主力训练卡:A100 40/80GB 辅卡:A10/A30(偏推理 & 轻训)
| 架构 | 典型训练卡 | AWS | Azure | GCP | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|---|
| Ampere | A100 | P4/P4d/P4de 系列:最多 8×A100,官方深度学习和生成式 AI 主力实例(Amazon Web Services, Inc.) | ND A100 v4 / NDm A100 v4:1–8×A100,专为大模型训练设计(Microsoft Learn) | Compute Engine 提供 A100 GPU,明确用于混合精度训练(Google Cloud Documentation) | ACK 异构集群支持 A100(与 T4/P100/V100 同列)(AlibabaCloud) | 高性能 GPU 集群提供 V100 & A100,用于自动驾驶/大模型训练(tencentcloud.com) | BM.GPU.A100 / BM.GPU4.8 等 shape:8×A100,官方 AI 训练主力形状之一(Oracle Docs) |
结论:Ampere/A100 是当前“主流通用训练卡”,除了最新 Hopper/Blackwell 以外,几乎所有大厂都会把 A100 当成标准训练配置。
A100具体参数:

5)Hopper 架构(H100 / H200)
主力训练卡:H100 80GB,新一代:H200 141GB
| 架构 | 典型训练卡 | AWS | Azure | GCP | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|---|
| Hopper | H100/H200 | P5 系列:8×H100;P5e/P5en 提供 H200,用于大规模 LLM 训练(Amazon Web Services, Inc.) | ND H100 v5:最多 8×H100,Azure 文档写明针对“大规模 DL 训练”(Zenn) | Compute Engine 公告支持 H100/H200/GB200 等新卡,用于混合精度训练(Google Cloud Documentation) | 公网资料显示阿里正在引入 H100/H800/H20 等做大模型训练(区域和配额差异较大) | 官方技术文频繁以 A100/H100/V100 作为训练平台示例,GPU 云服务也在引入 H100/H200 实例(tencentcloud.com) | BM.GPU.H100.8 / BM.GPU.H200.8:8×H100/H200,面向生成式 AI 训练(Oracle Docs) |
结论:H100/H200 是新一代高端训练和大模型专用卡,但价格和配额门槛都比较高,你可以在表里单独拉一个“高端大模型训练”段。
H100参数汇总:
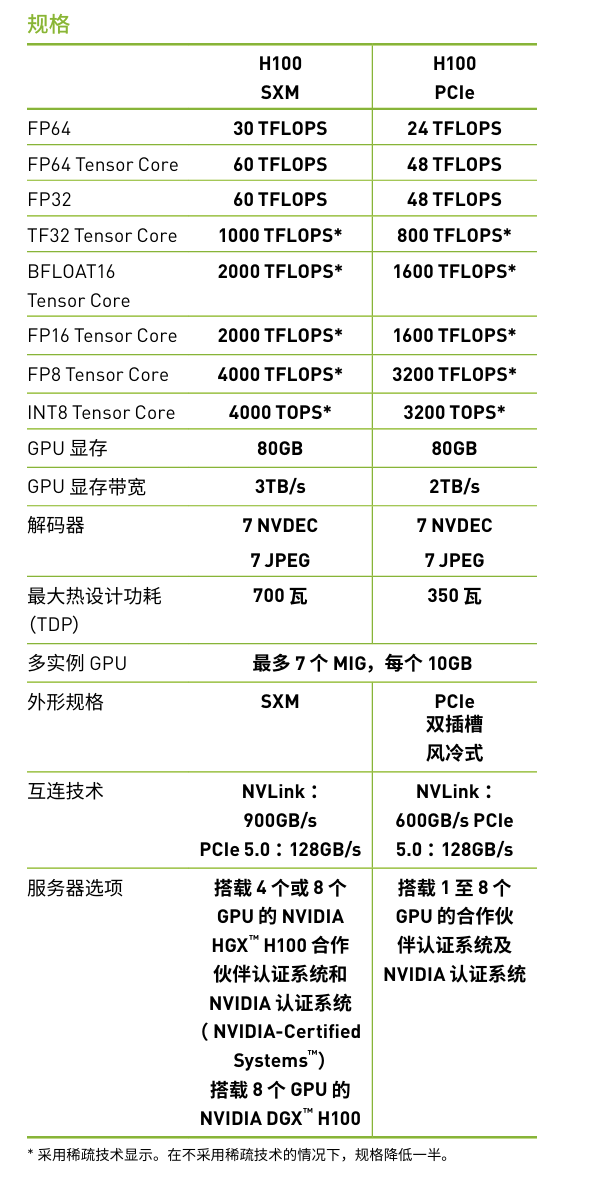
H200参数汇总:
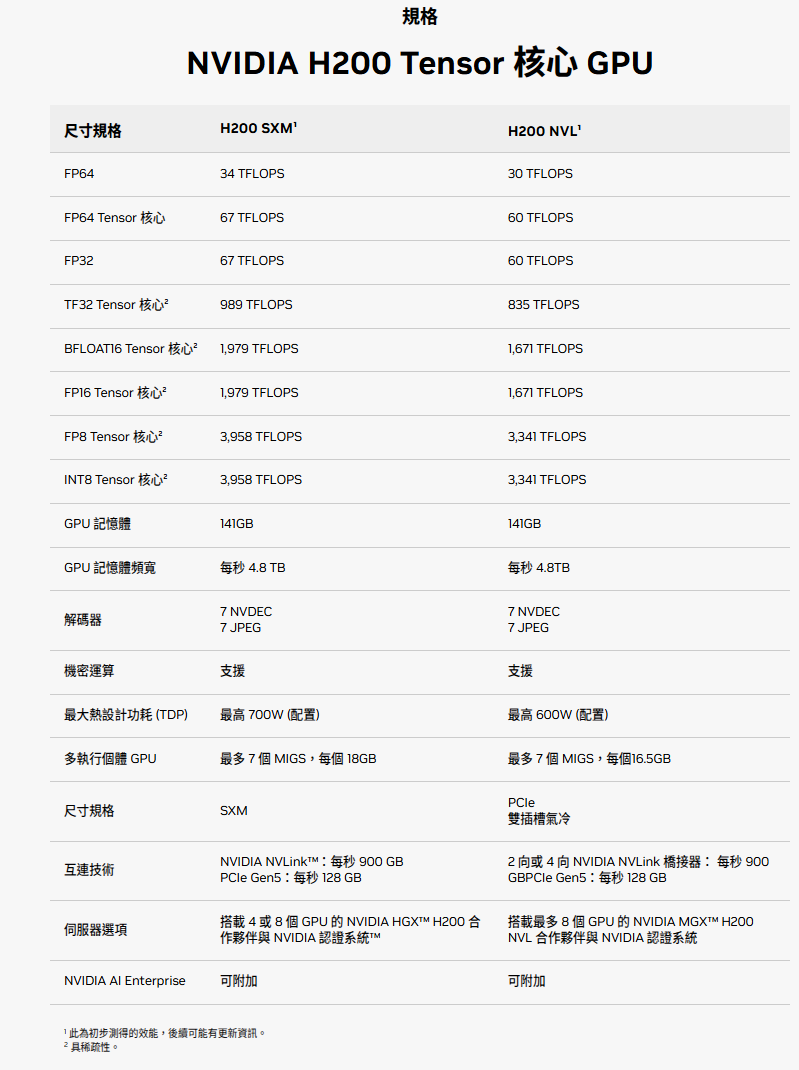
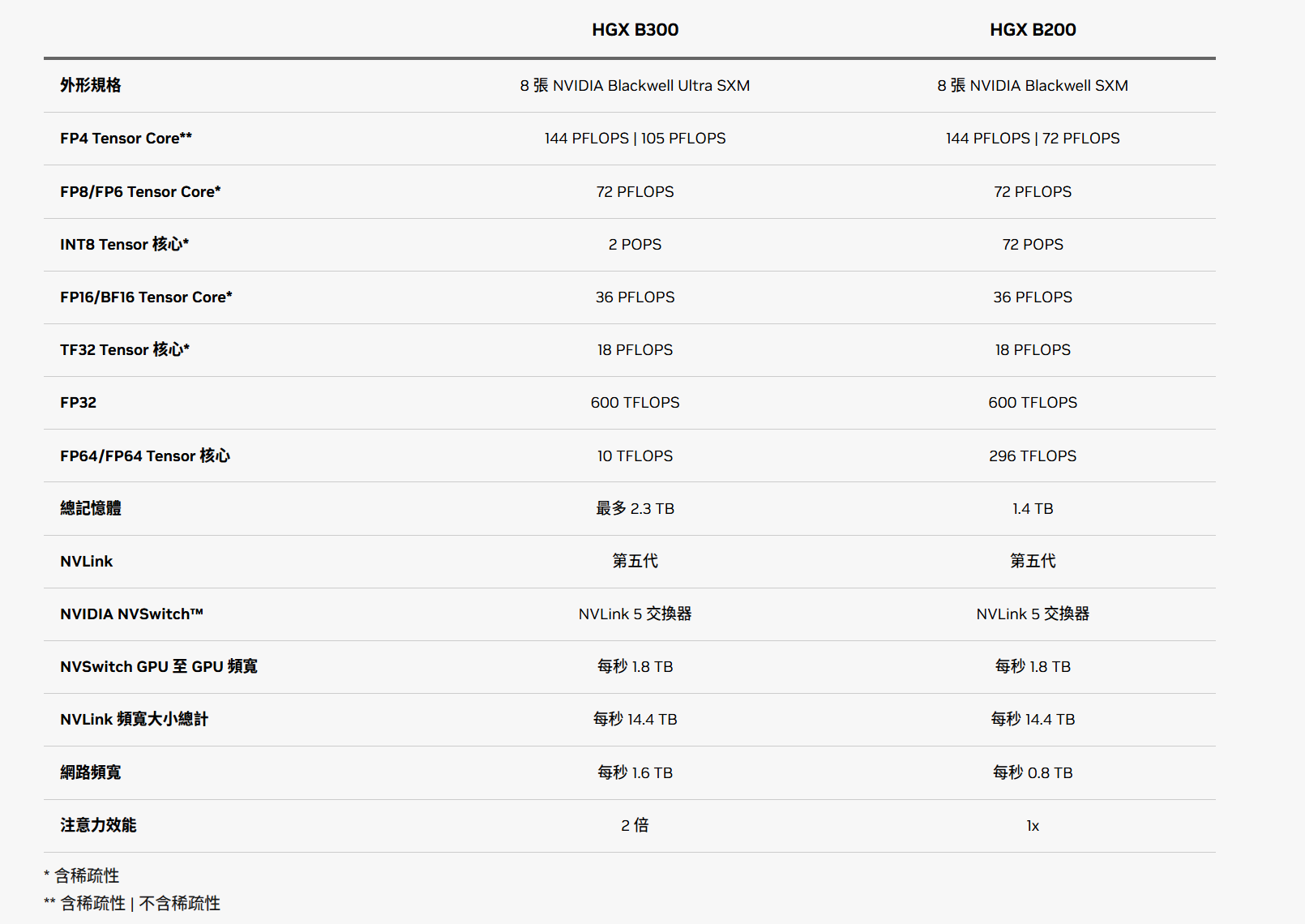
6)Blackwell 架构(B200 / GB200 / GB300)
这些是最新一代,目前主要在 GCP / Oracle / 部分超大云上逐步上线,用于超大规模 LLM/多模态训练。
| 架构 | 典型训练卡 | AWS | Azure | GCP | 阿里云 | 腾讯云 | Oracle Cloud |
|---|---|---|---|---|---|---|---|
| Blackwell | B200 / GB200 / GB300 | 公网信息显示 AWS 计划引入 Blackwell(尚在逐步落地阶段) | 尚未全面公开商用细节,多在合作新闻中出现 | Compute Engine / Cloud TPU 相关页面列出 GB200/GB300/B200 等 GPU,用于新一代大模型训练(Google Cloud) | 尚处于合作/试点阶段 | 很多技术文章提及将支持 B200/GB200 集群(偏向宣传和路线图) | Oracle 官方:提供 BM.GPU.B200.8 / BM.GPU.GB200.4 等形状,面向企业级生成式 AI(Oracle Docs) |
这代你可以在汇总中标为“前沿/试点”,和 A100/H100 这种“量产商用”区分开。
B200参数汇总:
推理卡算力汇总
| GPU | 架构 | INT4 | INT8 | FP16/BF16 | FP8 | FP32 | 备注(推理定位) |
|---|---|---|---|---|---|---|---|
| T4 | Turing | 130 TOPS | 65 TOPS | 8.1 TFLOPS | — | 8.1 TFLOPS | 云端经典推理卡(低功耗) |
| A2 | Ampere | ~45 TOPS | ~90 TOPS | ~11 TFLOPS | — | 4.5 TFLOPS | 超低功耗边缘推理 |
| A10 | Ampere | ~312 TOPS | ~156 TOPS | ~31 TFLOPS FP16 | — | 15.7 TFLOPS | 云推理性价比王 |
| A30 | Ampere | ~222 TOPS | ~111 TOPS | ~23 TFLOPS BF16/FP16 | — | 10 TFLOPS | 推理 + 轻训练通用大卡 |
| A40 | Ampere | ~150 TOPS | ~75 TOPS | ~20 TFLOPS FP16 | — | 14.2 TFLOPS | 图形 + 推理(视觉任务) |
| L4 | Ada | ~242 TOPS | ~121 TOPS | ~30 TFLOPS FP16 | — | ~15 TFLOPS | 新一代云推理主力(GCP G2) |
| L40 | Ada | ~500 TOPS | ~250 TOPS | ~90 TFLOPS FP16 | — | 45 TFLOPS | 大模型/多模态推理 |
| L40S | Ada | ~729 TOPS | ~364 TOPS | ~181 TFLOPS FP16 | — | 90 TFLOPS | L40 增强版:强推理性能 |
| H100(SXM) | Hopper | — | — | ~989 TFLOPS FP16(带稀疏) | ~1979 TFLOPS FP8(稀疏) | 67 TFLOPS | LLM 推理/训练两用王者 |
| H200(SXM) | Hopper | — | — | 与 H100 同级但受益于更大显存(141GB) | FP8 与 H100 类似(~2000 TFLOPS) | — | 面向大模型推理(≥70B) |
| B200(SXM) | Blackwell | > 2000 TOPS(FP4 等价) | — | FP16 较 H100 翻数倍 | FP4/FP8:H100 的数倍 | — | 次时代推理王者(FP4) |