前言
现有技术选型
我搜集了一些解决方案,要逐一对比看哪个方案更好
方案对比
对比维度:
转化效果,对GPU的依赖程度,转化速度
minerU
GPU的占用情况
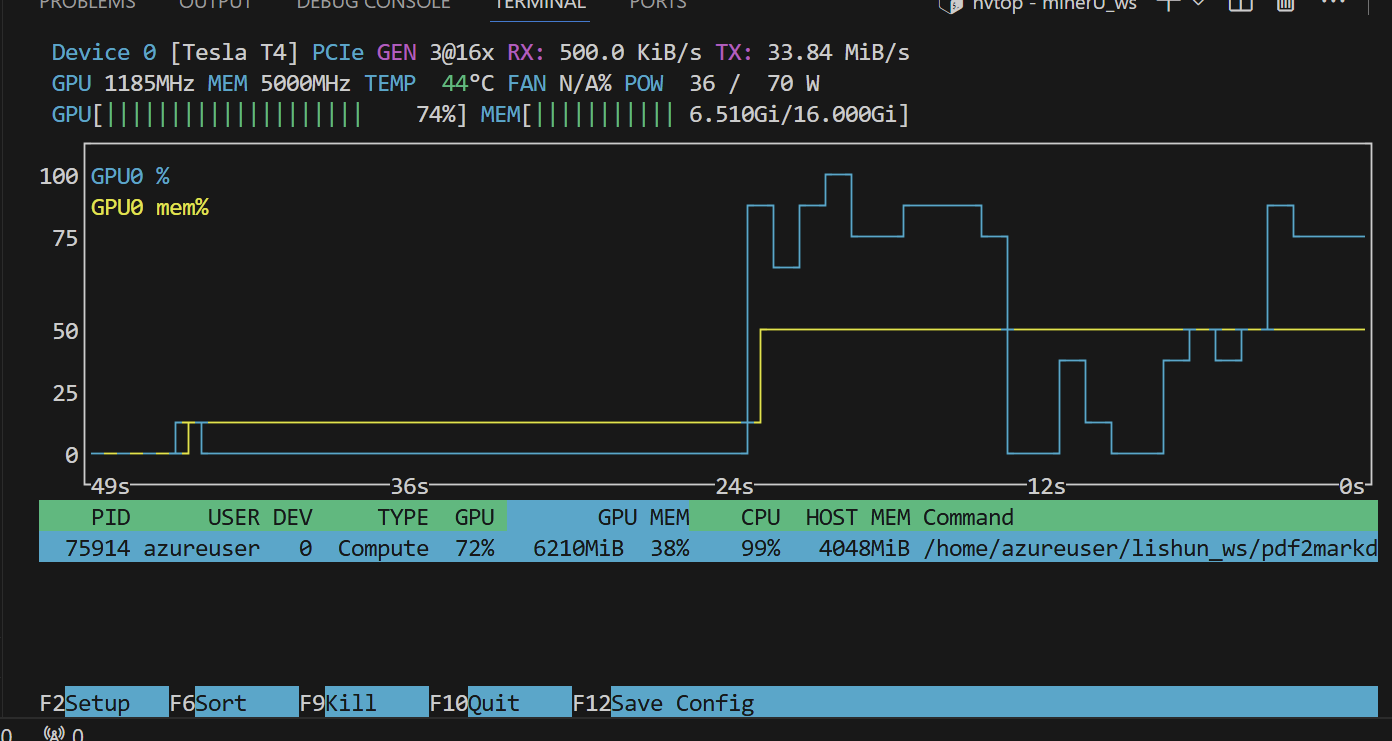
效果如下:
识别效果是真的好,markdown由于排版限制,文本表现可能不好,但是对大模型来说足够了

识别的效果非常非常好
LINK如下:
MonkeyOCR
环境挺复杂的,直接用docker拉起来吧
GPU的占用情况
对显存的压力很大
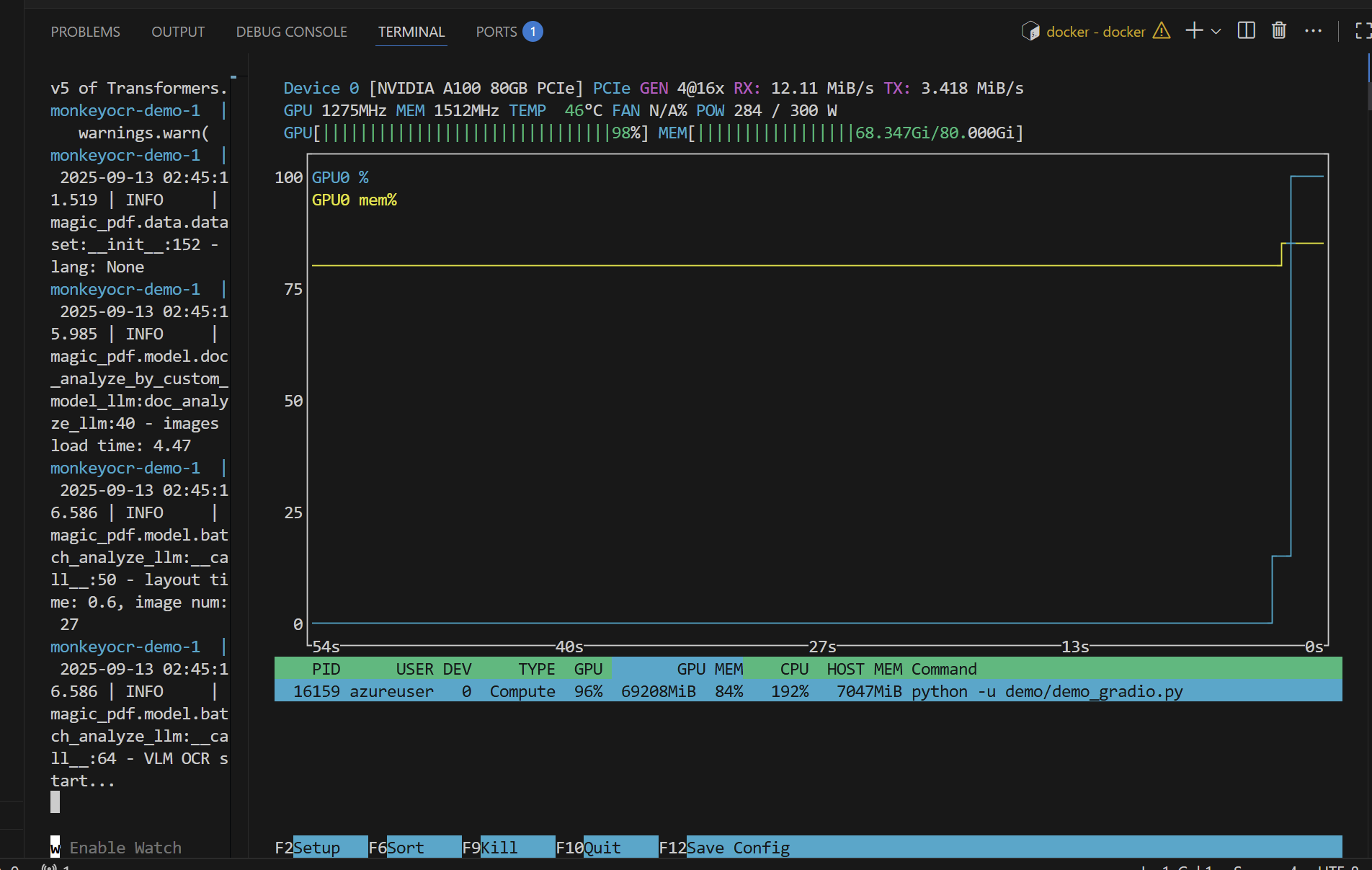
排版的效果也还行,但是目录的层次结构不够清晰,而且出现了部分项重复

OCR识别出的结果出现了大量的重复,4-MAC地址标签1CFI标准服务Onboard网络卡4-MAC 出现大约10多次的重复
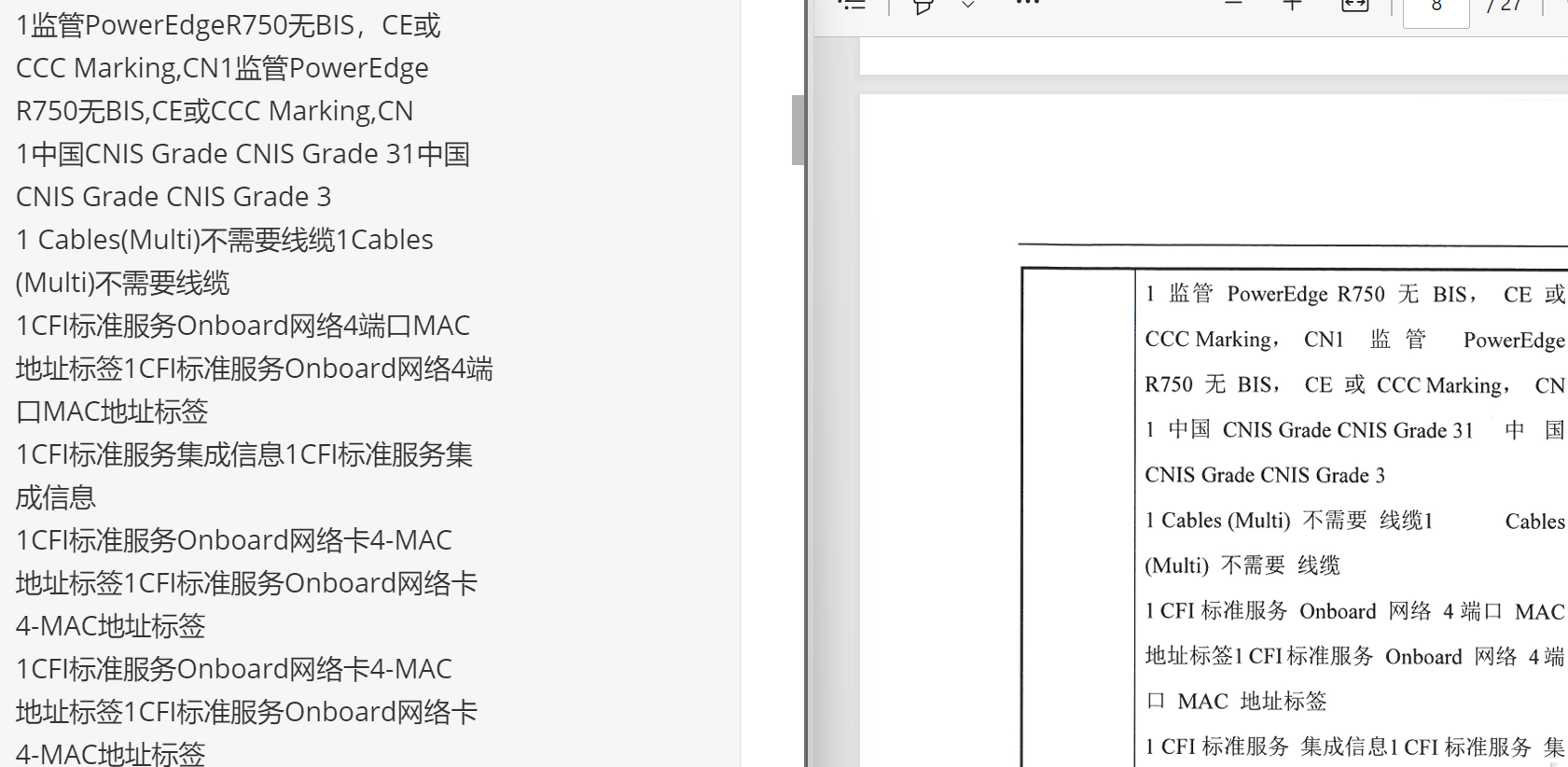
表格布局上比较不错,转化的速度也比较快,有较强的适应性,但是环境配置复杂且占用资源太高了【官方的模型会自动根据你的显存大小来调整占用】
markitdown
微软开源的工具
支持多种格式转换成markdown
得配合着插件来使用,Azure上的OCR文档识别对于文档布局的识别不是很给力,但是好在微软生态结合,调用API即可实现相应的功能,一键傻瓜式部署!