大模型推理引擎
vLLM
中小企业级私有化部署首选方案
项目地址:
大模型的推理主要瓶颈在带宽上
现在阶段的NV GPU 计算速度 >> 数据吞吐速度
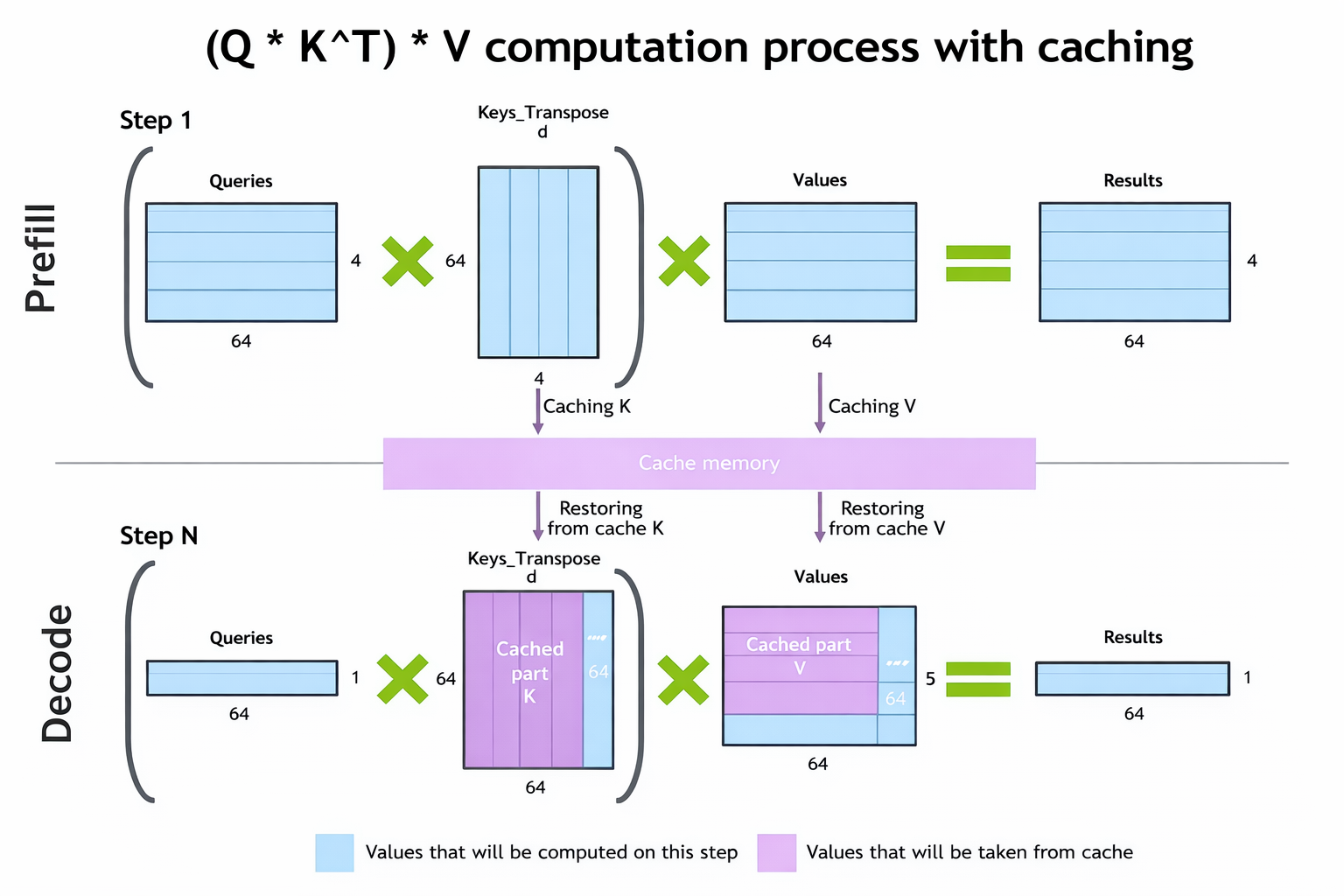
自回归模型会携带着每次的全文,每次推理只推一个Token,KVcahce缓存机制极大的加速了模型
梳理一下decoder模型的过程,
用户输入 -----> model ----> next_token > prefill 这一步是都要全量计算的
用户输入+[next_token,next_token++,…] ----> model —> next_token > Decode 这一部分就用 KV-Cache了
主要使用的技术: Paged KV + 连续调度
将GPU资源最大化利用
KV-Cache 演示
演示blog

使用 KV-Cache GPU只用很少的一部分需要计算,而且历史的K-V都会缓存,大大提升了计算的速度
- 选 vLLM:标准 OpenAI API 服务、追求生态成熟度、希望少改造快速落地。
TensoRT-LLM
极致吞吐需求,比较新的NV显卡可以采用
比如 A100 / H100 / H200
TensorRT极致的推理速度,配合NV的高带宽显卡,能榨干所有的性能
llama
针对个人用户
TGI
Hugging Face
SGLang
项目地址:
SGLang 在Agent 时代推理有一些优势,因为上下文中有大量的tools和系统提示词相关信息,Agent、多轮对话、重复前缀很多、强 JSON/grammar 约束
- 选 SGLang:Agent、多轮会话、共享前缀很多、强结构化输出、想自己做网关/路由/多模型调度
企业级应用方案
面向企业级的应用
1. NV-NeMo
项目地址:
2. vLLM
3.Triton
NV生态下的模型部署方案,配合trt-llm极限榨干nv生态的性能