OmniParser v2 模型部署
OmniParser 是微软开源的模型的作用是识别布局: 让 LLM 理解图片的含义,
- 输入: 图片
- 输出: JSON(坐标+是否可交互)
GitHub官方仓库为:
HuggingFace仓库:
环境
Azure Tesla T4 机器,显存 16G
我整合了一下,修复了一下问题,仓库地址为:
跟着 Readme 来启动即可
问题
官方的依赖写的十分抽象,一旦不维护立马炸, uv 版本不锁定,要人命
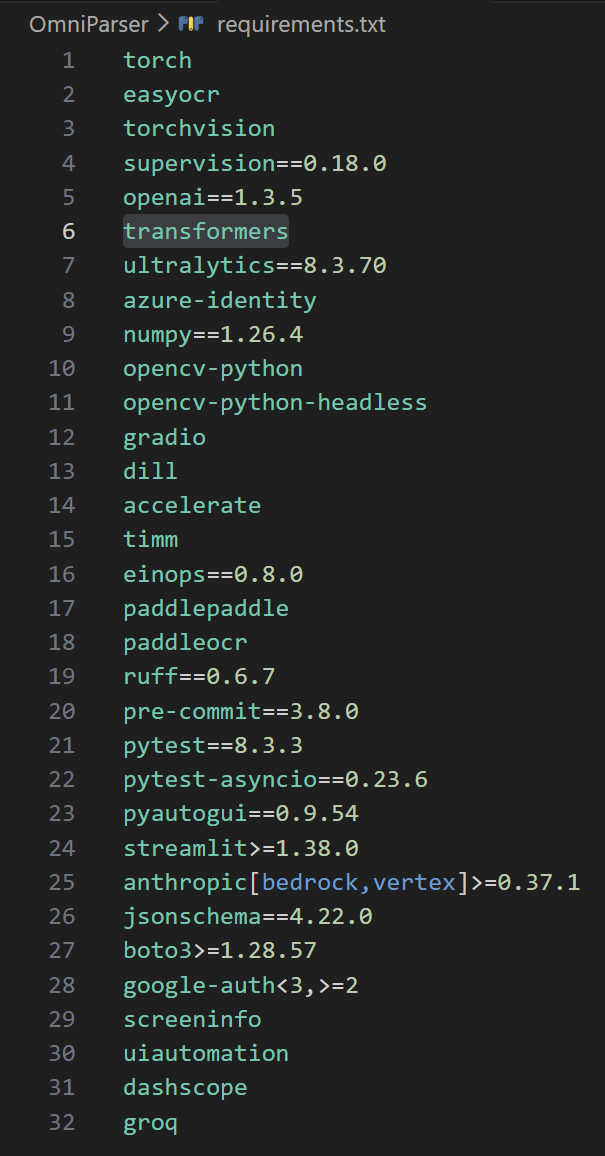
1. paddleocr版本不符
paddleocr 版本不符,官方的 requirements.txt 没有固定版本,如果按照官方的教程安装大概率会安到 paddleocr3.x 版本
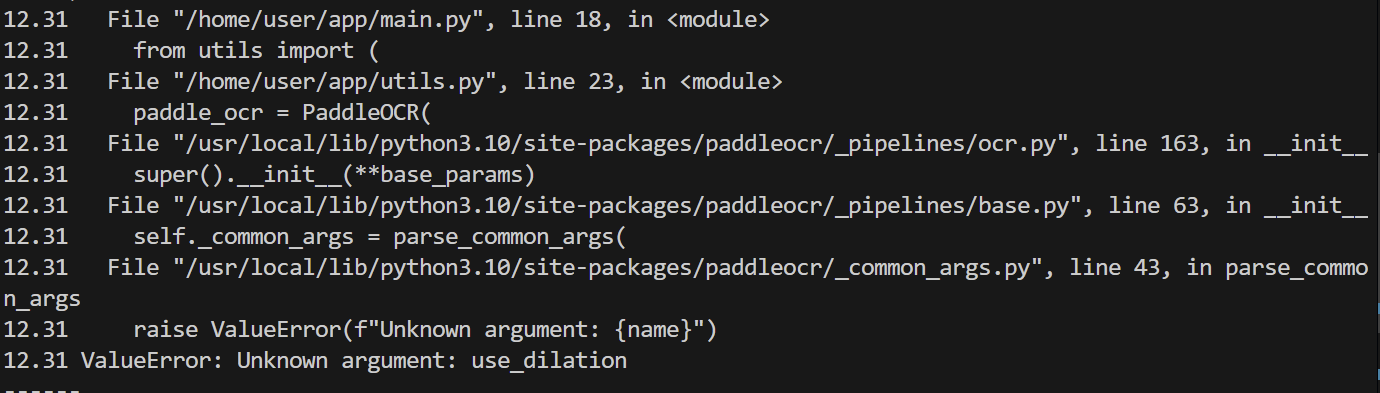
新版本的 paddle ocr 的api变动,需要额外适配,正确的做法是去找老版本
2. _supports_sdpa缺失报错
AttributeError: ‘Florence2ForConditionalGeneration’ object has no attribute ‘_supports_sdpa’
`torch_dtype` is deprecated! Use `dtype` instead!
Traceback (most recent call last):
File "/home/azureuser/lishun_ws/omini-parser-v2.0/OmniParser/gradio_demo.py", line 16, in <module>
caption_model_processor = get_caption_model_processor(model_name="florence2", model_name_or_path="weights/icon_caption_florence")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/azureuser/lishun_ws/omini-parser-v2.0/OmniParser/util/utils.py", line 67, in get_caption_model_processor
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.float16, trust_remote_code=True).to(device)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/azureuser/lishun_ws/omini-parser-v2.0/.venv/lib/python3.12/site-packages/transformers/models/auto/auto_factory.py", line 597, in from_pretrained
return model_class.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/azureuser/lishun_ws/omini-parser-v2.0/.venv/lib/python3.12/site-packages/transformers/modeling_utils.py", line 277, in _wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/azureuser/lishun_ws/omini-parser-v2.0/.venv/lib/python3.12/site-packages/transformers/modeling_utils.py", line 4971, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/azureuser/.cache/huggingface/modules/transformers_modules/microsoft/Florence_hyphen_2_hyphen_base_hyphen_ft/f6c1a25888ffc1d945ee8a1a77ac833c7303d46e/modeling_florence2.py", line 2535, in __init__
super().__init__(config)
File "/home/azureuser/lishun_ws/omini-parser-v2.0/.venv/lib/python3.12/site-packages/transformers/modeling_utils.py", line 2076, in __init__
self.config._attn_implementation_internal = self._check_and_adjust_attn_implementation(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/azureuser/lishun_ws/omini-parser-v2.0/.venv/lib/python3.12/site-packages/transformers/modeling_utils.py", line 2686, in _check_and_adjust_attn_implementation
applicable_attn_implementation = self.get_correct_attn_implementation(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/azureuser/lishun_ws/omini-parser-v2.0/.venv/lib/python3.12/site-packages/transformers/modeling_utils.py", line 2722, in get_correct_attn_implementation
self._sdpa_can_dispatch(is_init_check)
File "/home/azureuser/lishun_ws/omini-parser-v2.0/.venv/lib/python3.12/site-packages/transformers/modeling_utils.py", line 2573, in _sdpa_can_dispatch
if not self._supports_sdpa:
^^^^^^^^^^^^^^^^^^^
File "/home/azureuser/lishun_ws/omini-parser-v2.0/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1964, in __getattr__
raise AttributeError(
AttributeError: 'Florence2ForConditionalGeneration' object has no attribute '_supports_sdpa'
microsoft/Florence-2-base 模型导致的,新版本的 Transformers 库 更新支持了 PyTorch2x 版本增加了高性能注意力实现,而 transformers库 默认模型有属性 _supports_sdpa,而 microsoft/Florence-2-base模型是微软自己维护的,没来得及更新结果就是,一调用就炸了
- SDPA(Scaled Dot-Product Attention)
所以这一部分的补救,有两个方法:
- 降低 transformers 库的版本
- 手动修改 microsoft/Florence-2-base 模型,把缺的参数补上
- 换一个模型
解决方法
问题1:
1. 固定 paddle ocr的版本
由于原始版本没有固定 paddle ocr 版本,会导致 3.x 版本 和 2.x 版本 的 API冲突
paddle ocr 从 2.x 到 3.x版本api有大变动,会出问题
实测 项目使用 paddleocr ❤️ 版本最稳定,少量修改即使用
问题2:
方法1: 固定 transformers 版本
找一个低版本的 transformers ,这样就可以避免调用失败
方法2: 改模型
在模型的文件中增加 对应的属性变量即可解决报错问题
- 出现的解决方法
方法3: 或者更换模型
更换模型也能解决问题
测试效果
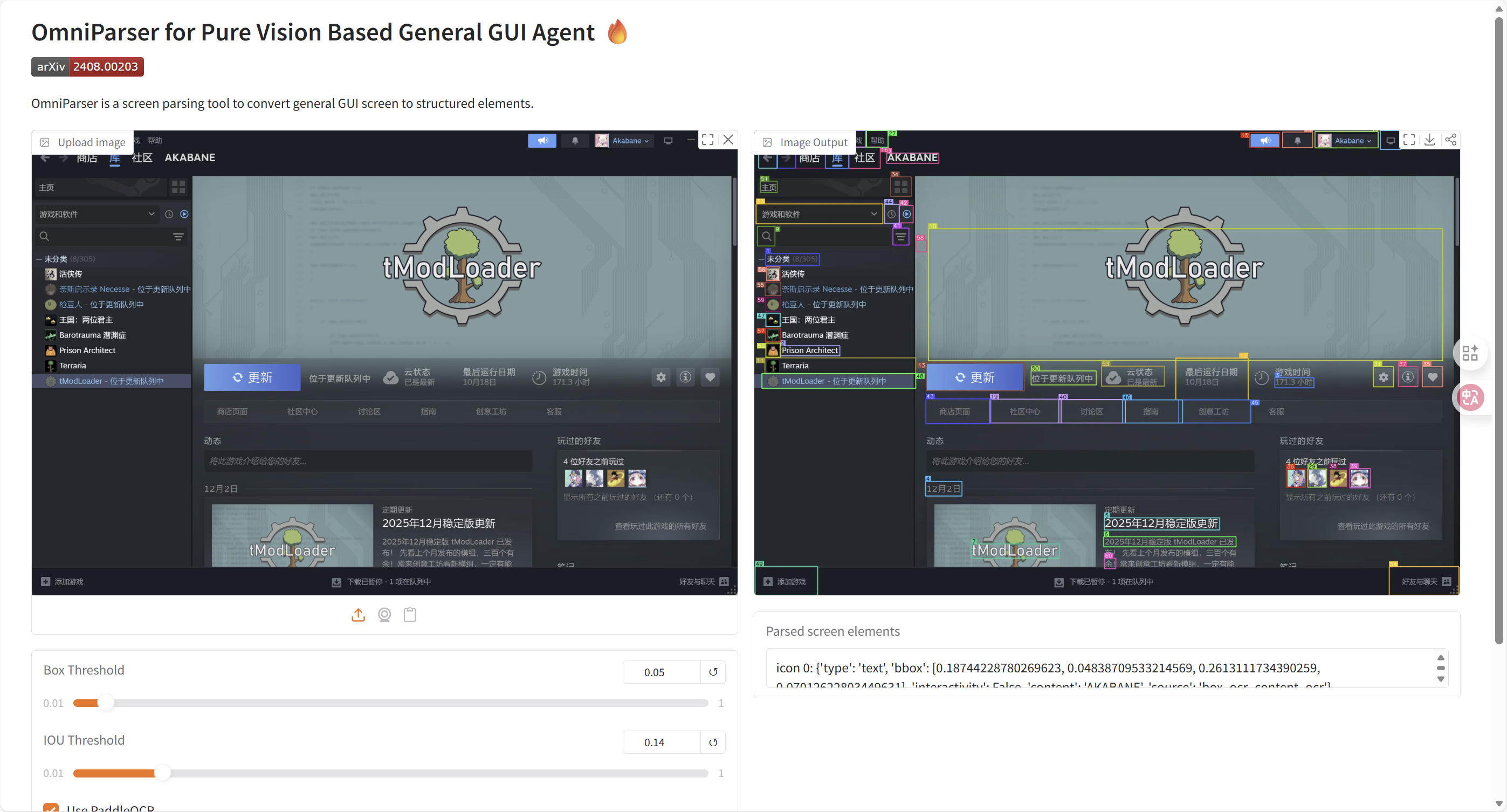
响应的大概数据如下:
icon 0: {'type': 'text', 'bbox': [0.18744228780269623, 0.04838709533214569, 0.2613111734390259, 0.07012622803449631], 'interactivity': False, 'content': 'AKABANE', 'source': 'box_ocr_content_ocr'}
icon 1: {'type': 'text', 'bbox': [0.015697138383984566, 0.26437586545944214, 0.09187442064285278, 0.29032257199287415], 'interactivity': False, 'content': ' (8/305)', 'source': 'box_ocr_content_ocr'}
icon 2: {'type': 'text', 'bbox': [0.036472760140895844, 0.46283310651779175, 0.1209602952003479, 0.48457223176956177], 'interactivity': False, 'content': ' Prison Architect', 'source': 'box_ocr_content_ocr'}
icon 3: {'type': 'text', 'bbox': [0.7373037934303284, 0.5315567851066589, 0.7927054762840271, 0.553295910358429], 'interactivity': False, 'content': '171.3J\\', 'source': 'box_ocr_content_ocr'}
......
icon 59: {'type': 'icon', 'bbox': [0.01591305620968342, 0.3585231900215149, 0.03732239827513695, 0.38975244760513306], 'interactivity': True, 'content': 'The image shows a black and white photo of a man and a woman', 'source': 'box_yolo_content_yolo'}
icon 60: {'type': 'icon', 'bbox': [0.49598175287246704, 0.9204674959182739, 0.5120115876197815, 0.9426710605621338], 'interactivity': True, 'content': 'The image shows a black and white photo of a street sign', 'source': 'box_yolo_content_yolo'}
- 效果图大概如下:
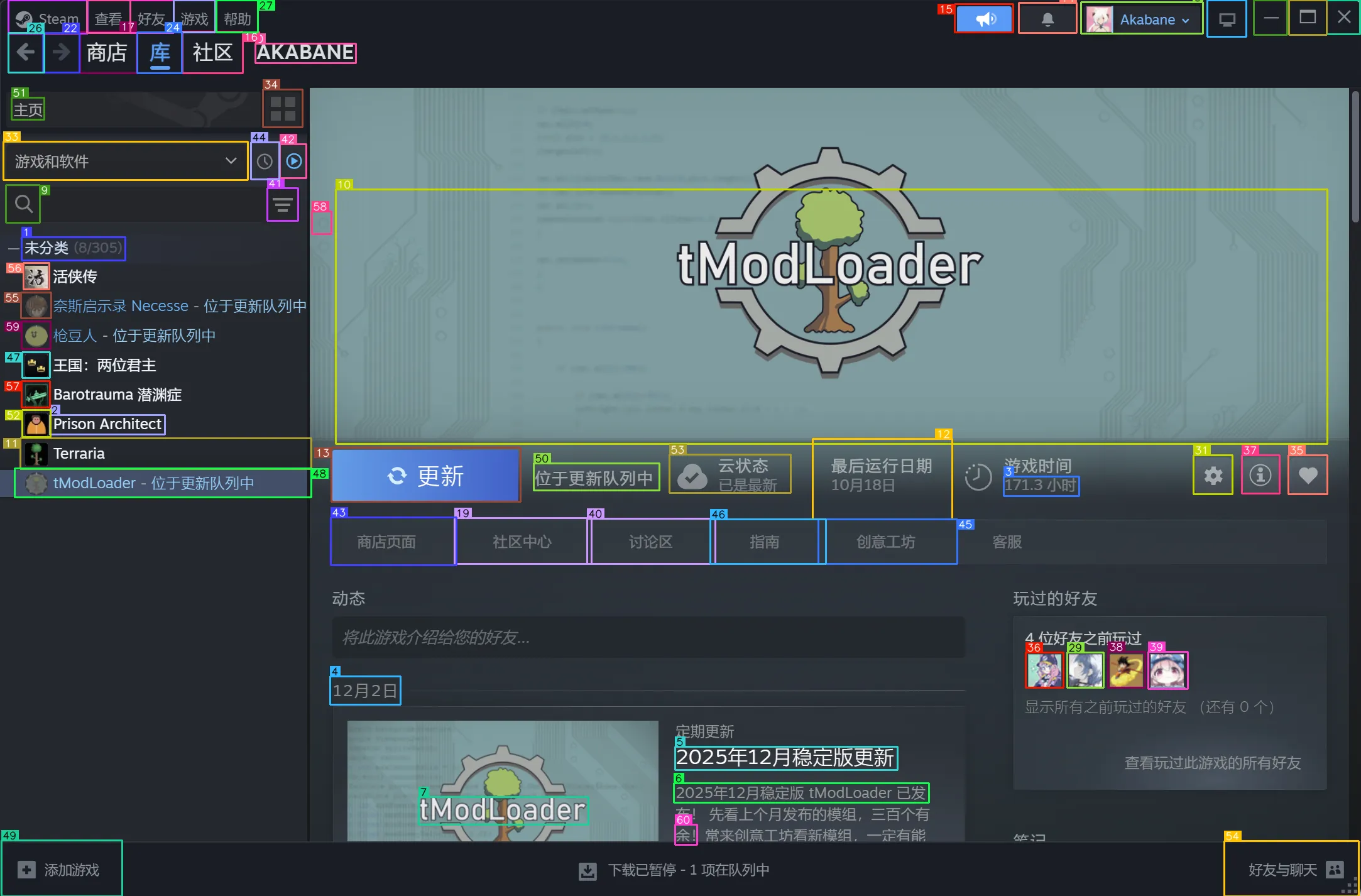
CUDA out of Memory 问题,这个应用有点吃显存,上传图片大了会炸炉子
如果做成应用最好有图片预处理的步骤,避免塞入一个巨大的图片导致炸炉子
抛砖引玉
微软开源的东西,研究学者写的,不够工程化开源了就撒手不管了,我找了些市面上同类的模型:
racineai/UI-DETR-1
这个模型卡片的 benchmark 如下:
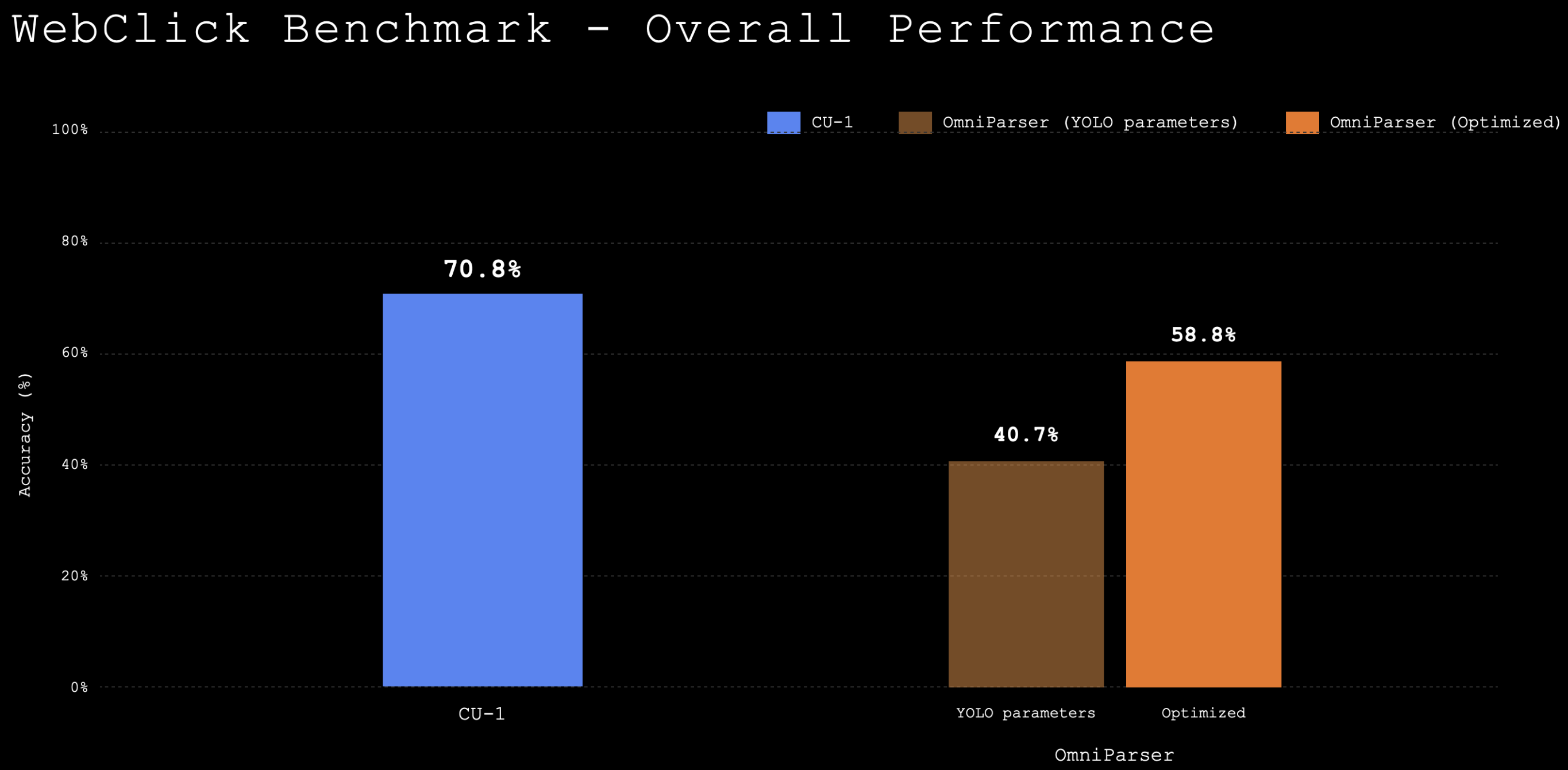
额外实验
本地模型接入MCP,工具式调用,实现大模型操作屏幕
需要的工具:
- 识别页面
- 点击操作