参考
Nvidia blog:
HF blog:
量化
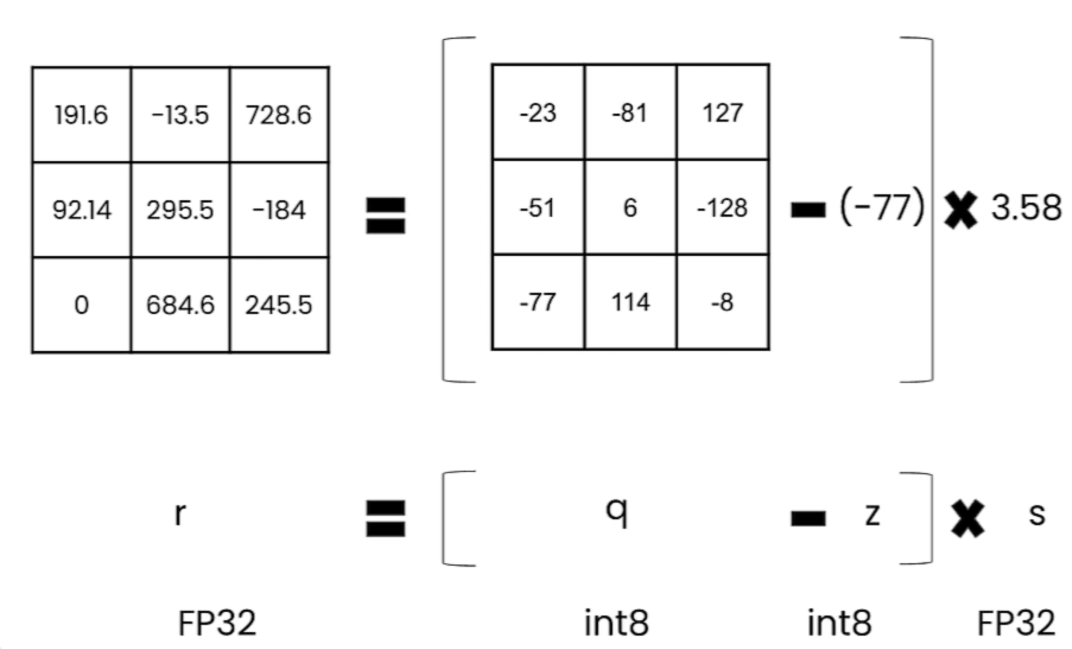
量化介绍
Quantization 量化
- 量化的目的是什么?
用更低位宽的数字 (如INT8/INT4/FP8) 去表示 权重/激活,从而减少显卡占用、加速推理、降低成本.
- 量化的收益是什么?
原模型权重 FP16/BF16:
- FP16:每个参数 16 bit = 2 bytes
- BF16:也是 2 bytes(指数不同)
量化后:
- INT8:1 byte
- INT4:0.5 byte
- FP8:1 byte(但仍是浮点)
所以量化的直接收益通常是:
- 显存下降 2x~4x
- 吞吐提升(取决于硬件与算子是否支持)
- 部署成本下降(能用更小 GPU)
- 量化的对象是什么?
- 权重量化(Weights
推理时权重固定,量化非常成熟。
- 激活量化(Activations
激活值是推理过程中产生的中间结果,分布随输入变化。
- 优点:潜在速度更快(全 INT8 GEMM)
- 缺点:更容易掉点,需要校准数据和更复杂方案
- KV Cache 量化
LLM 长文本的 KV cache 显存非常大。
- 适合:长上下文、RAG、多轮对话
- 可节省大量显存(甚至比权重更关键)
分类
PTQ
Post-Training Quantization ,训练后量化
不重新训练模型,直接量化 速度快、成本低、最常用。
典型代表:
- GPTQ
- AWQ
- SmoothQuant
- bitsandbytes int8/int4
QAT
Quantization-Aware Training,量化感知训练
在训练过程中模拟量化误差,适配量化
- 优点:精度更好
- 缺点:需要训练资源 & pipeline
- 常见于:端侧、小模型、特定任务
LLM推理领域目前 PTQ为主流
量化技术
GPTQ
特点:
- 逐层量化并优化误差
- 常用 4-bit weight-only
优点:
- 精度好(4bit里很强) 缺点:
- 量化过程慢
- 对推理框架兼容性一般(依赖实现)
适合:离线量化一次,长期部署
AWQ
Activation-aware Weight Quantization
核心思想:
权重要量化,但要考虑激活分布(挑“重要通道”保护)
优点:
- 精度通常比普通 4bit 更好
- 比 GPTQ 更快更易用
- vLLM 对 AWQ 支持非常成熟(尤其是 AWQ-Marlin)
适合:生产部署 INT4 的首选之一
SmoothQuant
权重+激活的 INT8
核心思想:
把激活中的“难量化峰值”平滑转移到权重上
效果:
- 全 INT8 推理潜力大
- 常见于 TensorRT、ONNXRuntime 的 INT8 路线
缺点:工程复杂度高,需要校准
bitsandbytes
常见:
load_in_8bit- NF4/FP4 4bit(QLoRA 常用)
特点:
- 方便
- 但推理吞吐不一定最好(看硬件和 kernel)
量化注意事项
物理GPU是否支持一些数据类型很重要
比如 FP8 是 H100/H200 (Hoper架构) 才支持的
最佳的做法是 INT8 比较稳定
不是所有的框架都能用上Tensor Core
要选择正确的推理框架
量化工具
vLLM工具
AutoAWQ
AutoAWQ 已经放弃了,但vLLM团队接手维护了一个新的,并且做了进一步扩展
llm-compressor
项目地址
vLLM
tensorRT / tensorRT-LLM
NV生态家族不可获取的一部分
tensorRT-LLM
Hugging Face工具
Optimum
optimum: