倒排索引
倒排索引(Inverted Index)发明的目的,本质只有一个:
让“从词找文档”这件事,从不可用,变成可规模化、可工程化、可实时的事情。
介绍
比如下列的文本
Doc1: 我喜欢学习人工智能
Doc2: 我喜欢学习机器学习
Doc3: 人工智能改变世界
Doc4: 学习让世界更美好
传统的索引做法是:
Doc1 → [我, 喜欢, 学习, 人工智能]
Doc2 → [我, 喜欢, 学习, 机器学习]
Doc3 → [人工智能, 改变, 世界]
Doc4 → [学习, 让, 世界, 更, 美好]
这种结构的核心问题是:
它适合“从文档看内容”,不适合“从词找文档”。
你想查「人工智能」,必须遍历所有文档,复杂度为O(N)
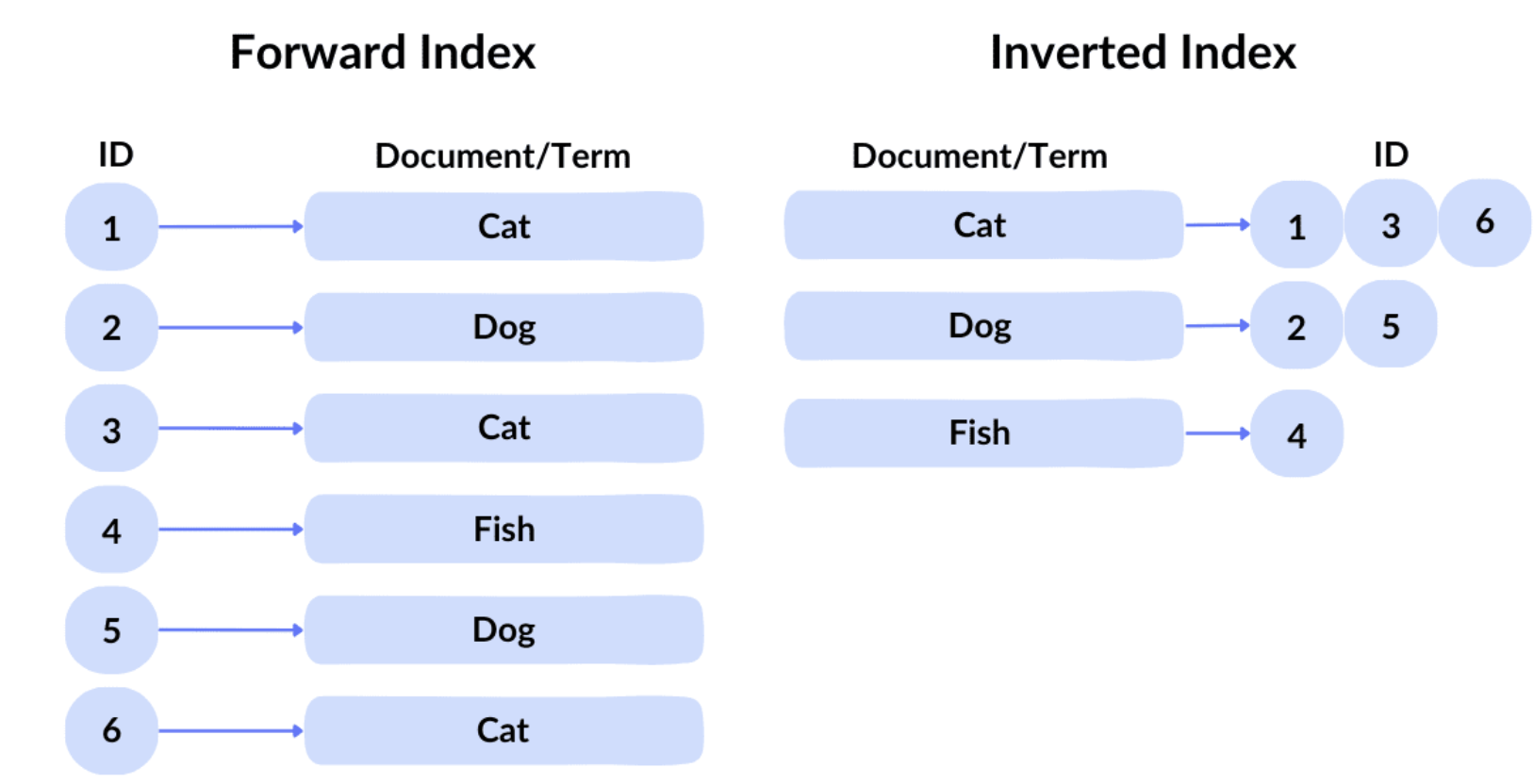
而倒排索引的做法为:
- 倒排索引做了一个方向反转:
- 对文本进行 Tokenize / 分词
- 以 token 作为 key
- 文档列表(posting list)作为 value
我 → [Doc1, Doc2]
喜欢 → [Doc1, Doc2]
学习 → [Doc1, Doc2, Doc4]
人工智能 → [Doc1, Doc3]
机器学习 → [Doc2]
改变 → [Doc3]
世界 → [Doc3, Doc4]
让 → [Doc4]
更 → [Doc4]
美好 → [Doc4]
这样我在查找一个词时,时间复杂度从 O(N) 降为 O(1) + posting list 扫描
引入的新问题
- 公共词太多(信息熵极低)
例如:
的、是、了、and、the、to、我、你、他
特点:
- 几乎出现在所有文档
- 对区分文档 毫无帮助
- posting list 极长
不但无助于排序,还会拖慢查询
- 词表(vocab)爆炸
例如:
- 人名
- 错别字
- 只出现 1 次的词
- OCR 噪声
- 非法 token
结果:
- vocab 数量暴涨【极其稀疏】
- posting list 极短
- 空间浪费
- cache miss 严重
工业界的选择
Lucene / Elasticsearch / OpenSearch 的共识:
不是“所有词都值得被索引”
算法介绍
信息检索(Information Retrieval, IR)
主流的打分算法
1.TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种常用的文本挖掘方法,用于衡量一个词语在文档集合中的重要性。
核心思想
TF-IDF 的核心思想是: 一个词是否“重要”,取决于它在“当前文档中是否常见”,以及它在“整个语料中是否罕见”。
计算公式
- TF(词频)
TF 为词频,表示某个词在所有文档中出现的稀有程度
公式为: $$ TF = \frac{某词在当前文档出现的次数}{当前文档的总词数} $$ OR $$ TF(t,d)=\frac{f(t,d)}{\sum_{t’\in d}f(t’,d)} $$
- IDF
IDF 衡量某个词在所有文档中出现的稀有程度。 公式为: $$ IDF = log(\frac{总文档数}{包含该词的文档数 + 1}) $$ OR $$ IDF(t)=log(\frac{N}{df(t)+1}) $$
-
N:文档总数
-
df(t):包含词 ttt 的文档数
-
+1:防止除零(平滑)
- TF-IDF
综合词频和逆文档频率,反映词语对当前文档的区分能力。 公式: $$ \text{TF-IDF} = TF \times IDF $$
最终效果
| 情况 | 结果 |
|---|---|
| 高频 + 全文档常见 | 权重极低 |
| 文档内高频 + 全局稀有 | 权重极高 |
2.BM25
BM25 全称Okapi BM25
工业默认算法
TF-IDF 在工程上有两个问题:
- 长文档天然占优势
- TF 线性增长不合理
BM25 是 TF-IDF 的工程改进版
Lucene / Elasticsearch / OpenSearch 默认使用 BM25
核心思想:
- TF 增益递减(出现 100 次 ≠ 100 倍重要)
- 文档长度归一化
- 参数可调,适合不同业务
你可以理解为:
BM25 = 可控、稳定、可调参的 TF-IDF
BM25打分公式
对一个查询 $$q$$ 和文档 $$D$$,BM25 的总分是把查询里每个词的贡献相加: $$ \mathrm{score}(D, q)
\sum_{t \in q} \mathrm{IDF}(t) \cdot \frac{ f(t, D),(k_1 + 1) }{ f(t, D) + k_1 \cdot \left( 1 - b + b \cdot \frac{|D|}{\mathrm{avgdl}} \right) } $$ 各符号含义:
- **t:**查询中的某个词(term)
- **f(t,D):**词 $t$ 在文档 $D$ 里的出现次数(TF)
- **|D|:**文档长度(通常是分词后的 token 数)
- **avgdl:**全库文档平均长度
- **k_1:**控制 TF “饱和”速度(常用 1.2~2.0)
- **b:**控制长度归一化强度(0~1,常用 0.75)
- **IDF(t):**逆文档频率(下面说)
BM25里的DIF
常见 BM25 IDF(Okapi 版本): $$ IDF(t)=log(\frac{N-n_t+0.5}{n_t+0.5}+1) $$
-
N:总文档数
-
n_t:包含词 ttt 的文档数(DF)
直觉:越稀有的词,IDF 越大;越常见的词,IDF 越小。
具体做法
1) 用倒排索引取候选文档
对查询分词:q=[t1,t2,…] q = [t_1, t_2, …]q=[t1,t2,…] 用倒排索引拿到每个 term 的 posting list,然后 union / intersection 得到候选文档集合。
2) 对每个候选文档计算 score
对每个 term:
- 从 posting list 里拿到 f(t,D)f(t,D)f(t,D)(很多系统的 posting 里直接存 TF)
- 取文档长度 ∣D∣|D|∣D∣
- 用全局统计得到 N,nt,avgdlN, n_t, \text{avgdl}N,nt,avgdl
- 代入公式算该 term 的贡献并累加
3) 按 score 排序输出 TopK
score 高的排前面。
3. 语义相关度
倒排索引有一个无法绕过的本质限制:
它只理解“词”,不理解“意思”
例如:
“我想买一部手机”
“有没有性价比高的安卓”
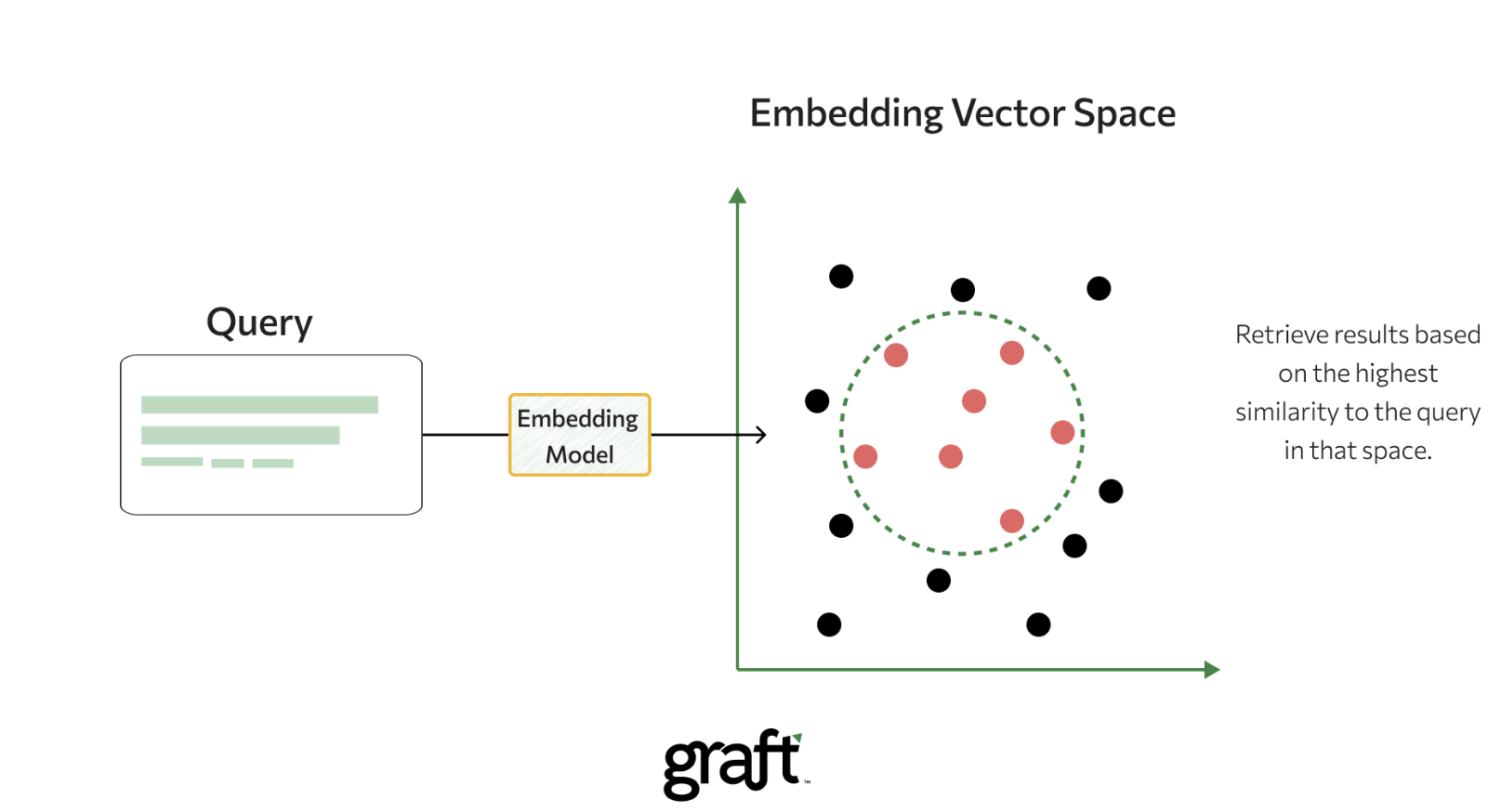
语义检索的做法
- 使用模型将文本转为向量(Embedding)
- 在向量空间中做相似度搜索(ANN)
ANN(Approximate Nearest Neighbor)是一类用于高维向量空间的近似相似度搜索算法, 通过牺牲极少量精度,换取数量级的性能提升, 是语义检索与向量数据库能够工程化落地的关键技术【此处暂时不展开了】
常见方式:
- 倒排索引 → 粗召回
- 向量检索 → 语义召回
- Rerank → 精排
这种语义的思想最早在1953年就有出现
2013年的 Word2Vec 才实现了工程上可用
实践
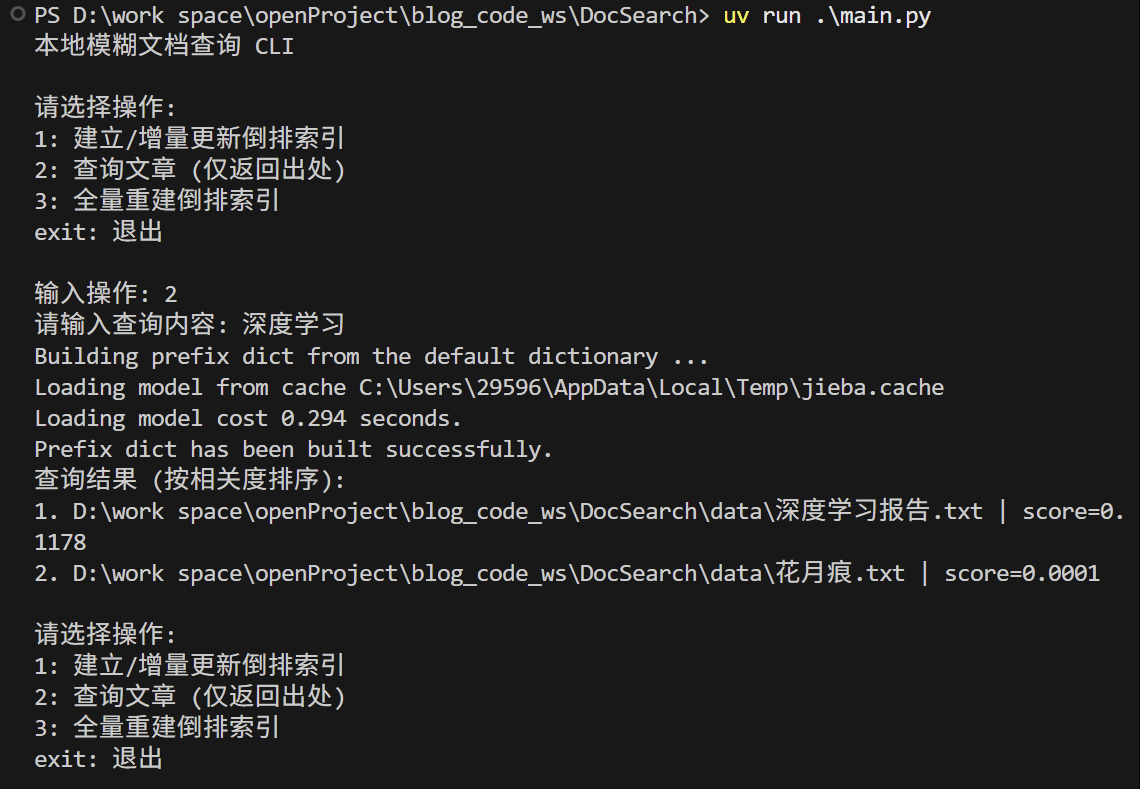
1. 本地文档模糊查询
使用的技术为:
- 模糊匹配
- 倒排索引
代码仓库在:
采用的三方库有:(这些库的性能超乎意料,速度出奇的快)
jieba —> 中文分词
rapidfuzz ----> 高性能的模糊字符串匹配
2. OpenSearch
使用开源的 opensearch 来做简单演示
OpenSearch 是aws基于Elasticsearch 一个分支的版本
代码仓库在:
Docker启动服务
docker pull opensearchproject/opensearch:3
docker pull opensearchproject/opensearch-dashboards:3
opensearch-dashboards 可视化窗口
3. 语义检索
代码仓库在:
大概演示的效果,RAG有很多工程实践的难点,想做好其实并不容易
