私有化部署模型
我们模拟一个客户的需求,做一个需求模拟与分析,并做一个实验并测试
需求
私有化部署LLM模型,需求如下:
原始需求【困难】
精度支持:
- FP8
- INT8
- FP16
能切换精度
量化方案支持:
- E4M3
- E5M2
模型要求:
-
Qwen3-32B
-
Qwen3-14B-Instruct
Agent方案
| Agent 类型 | 模型参数 | 输入 Token 数量 | 输出 Token 数量 | 数量 |
|---|---|---|---|---|
| 主 Agent | Qwen3 32B | 3000-20000 | ≤700 | 1 |
| 子 Agent | Qwen3 32B | 3000-10000 | ≤800 | 3 |
| 子Agent | Qwen3 14B | 3000-10000 | ≤800 | 4 |
| 指标类型 | 要求值 | 说明 |
|---|---|---|
| 并发处理能力(QPS) | 峰值≥100 | 多用户并发请求场景下稳定达标 |
| 首次 Token 输出时间(TTFT) | ≤3000ms | 从请求发起至首个输出 Token 的响应时间 |
| 后续 Token 输出时间(TPOT) | 20ms~30ms | 连续输出 Token 的平均间隔时间 |
| 端到端推理时间 | 5s~6s | 7 个子 Agent 并行执行 + 主 Agent 串行执行总耗时 |
实验简化【test】
精度支持:
- INT8
- FP16
- E4M3
- E5M2
能切换精度
量化方案支持:
-
AWQ
模型要求:
-
Qwen3-32B
-
Qwen3-14B-Instruct
方案
原始
只能上 K8S + Kserver + API Gateway
这个要求比较高,需要后面评估
简化
硬件
H100 * 2
A100 * 4
Azure 选型
编排
手动编排,编写脚本【不会k8s】
推理方案
- NV Trition
推理引擎
-
vLLM
-
tensorRT-LLM
代理与负载均衡
- lite-llm
- vLLM-router
网关管理
- one-api 【简单的做法】
- Higress 【阿里开源的API网关管理】
监控方案
- Prometheus 【数据监控】
- Grafana 【可视化】
- DCGM Exporter 【NV GPU监控】
其实这一套做下来也是很复杂的,这就是一套标准的云原生方案
测试工具
- vLLM benchmark
架构如下
大致如下
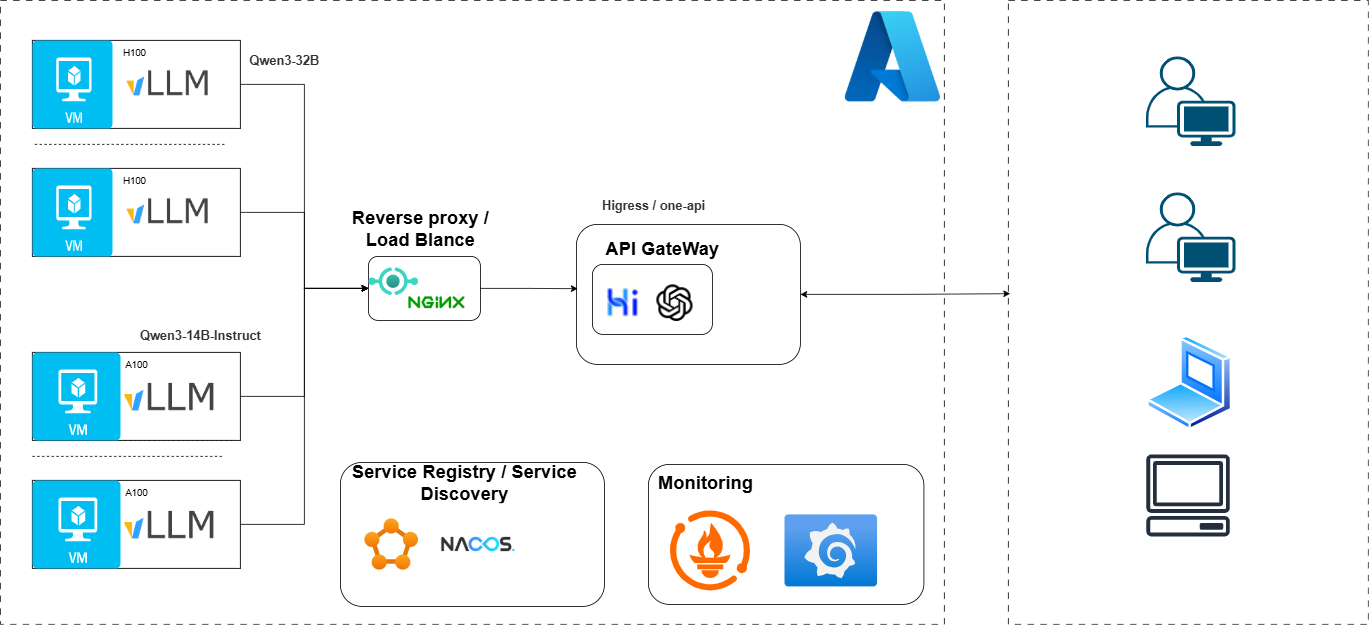
实施
只做简单的,难得不会