为什么 Web 请求不适合跑长任务
一句话先说结论:HTTP 请求适合“快速交互”,不适合“长时间占用计算资源的后台作业”。
很多人第一次接触长链路任务,都会下意识地这样写:
- 前端发一个请求
- 后端开始做 OCR、AI 分析、导出 Excel、转码
- 前端一直等到结果返回
这在 demo 里看起来很直接,但到了真实线上环境,通常很快就会出问题。
Web 请求的默认假设
HTTP 的设计心智,其实更接近下面这个模型:
sequenceDiagram
autonumber
participant U as 用户
participant B as 浏览器
participant S as 服务端
U->>B: 点击按钮
B->>S: 发起 HTTP 请求
S-->>B: 很快返回结果
B-->>U: 页面更新
它默认假设的是:
- 请求会在毫秒级到秒级完成
- 连接不会被长期占用
- 用户希望立刻看到响应
- 服务端线程、进程、连接池都要尽快释放
所以 Web 请求最擅长的是这类事情:
- 查一条数据
- 提交一个表单
- 新建一条记录
- 做一次轻量计算后返回页面
什么任务算“长任务”
只要任务满足下面任意一类,就不要再把它当成普通同步请求了:
- 执行时间长:比如 10 秒、30 秒、2 分钟
- 资源消耗大:CPU、GPU、内存、第三方配额都很贵
- 步骤很多:不是一步完成,而是多阶段推进
- 失败概率高:依赖外部服务、模型接口、文件系统、网络波动
- 需要进度:用户会关心“现在跑到哪一步了”
常见场景有:
- 导出 10 万行 Excel
- 上传合同后做 OCR + 结构化提取
- AI 生成图片、视频、报告
- 大文件转码与切片
- 批量发消息、批量同步数据
如果硬塞进同步请求,会发生什么
1. 超时
长任务最先撞上的,通常不是业务逻辑,而是各种超时:
- 浏览器等待超时
- Nginx / 网关超时
- 负载均衡超时
- 上游 SDK 超时
也就是说,任务可能还在后台算,连接却已经断了。
2. 资源被长时间占用
如果一个请求跑 2 分钟,那么这 2 分钟里:
- 一个 worker 被长期占住
- 一条连接被长期占住
- 整体吞吐量会迅速下降
请求一多,就会出现“前面几个任务没做完,后面的人全堵住”的现象。
3. 用户体验很差
用户看到页面一直 loading,并不会觉得“系统在努力工作”,更可能会觉得:
- 卡住了
- 网络断了
- 要不要刷新一下
一旦刷新、重复点击、重试提交,就会引出重复任务、重复扣费、重复写入的问题。
4. 工程能力几乎为零
同步长请求还有一个更大的问题:它几乎没有任务系统该有的能力。
| 维度 | 纯 Web 同步 | 任务系统 |
|---|---|---|
| 超时控制 | 很弱 | 强 |
| 削峰填谷 | 没有 | 有 |
| 进度展示 | 没有 | 天然支持 |
| 重试恢复 | 很难 | 容易做 |
| 并发控制 | 粗糙 | 可配置 |
| 审计追踪 | 困难 | 方便 |
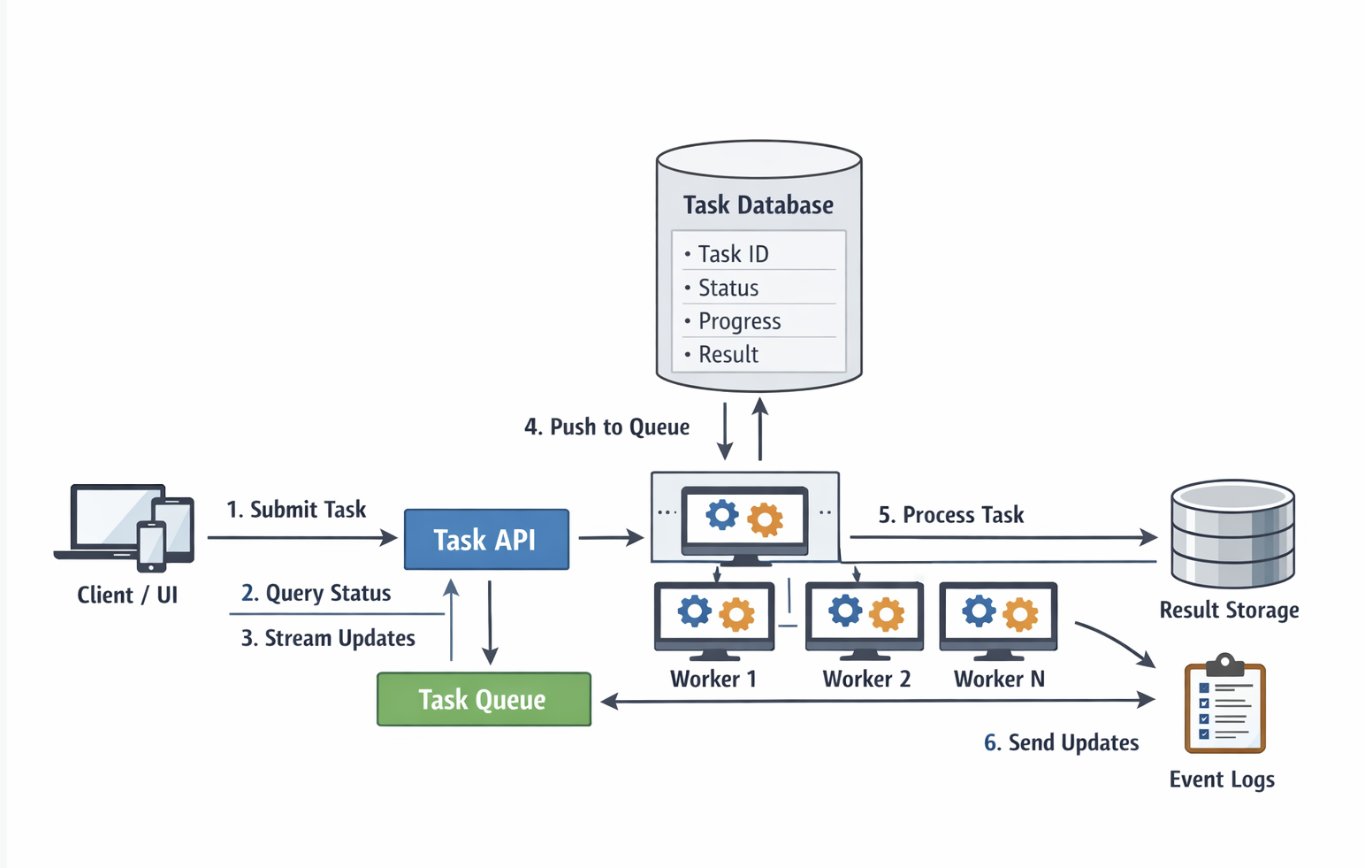
长任务真正的模型
长任务的真实过程更像这样:
flowchart LR
A[用户提交任务] --> B[创建任务记录]
B --> C[进入队列等待]
C --> D[Worker 执行]
D --> E[多阶段推进]
E --> F[完成或失败]
F --> G[用户查询结果]
也就是说,长任务的核心不是“一个请求跑很久”,而是:
发起、排队、执行、更新状态、查询结果,这是一整个生命周期。
这时你就应该把它从“请求处理”升级成“任务处理”。
为什么任务系统更适合
把长任务改造成任务系统以后,请求本身只负责做两件事:
- 接收任务
- 立刻返回任务 ID
后面的排队、执行、失败重试、状态更新,都交给后台系统处理。
这样做的原因很直接:
- 请求层要快,才能扛住高并发
- 执行层要稳,才能处理慢任务和失败重试
- 用户要看到状态,才知道系统不是“卡死”了
一个最小案例:导出 10 万行 Excel
同步写法
点击“导出”
-> 后端查询数据库
-> 组装 Excel
-> 上传文件
-> 返回下载地址
如果这个过程要 90 秒,那么前端就要等 90 秒。期间任意一个链路超时,用户只会看到失败。
异步写法
点击“导出”
-> POST /export-tasks
-> 立即返回 task_id
-> 后端异步生成文件
-> 前端轮询 /tasks/{id}
-> 完成后展示下载链接
对应的 HTTP 交互可以长这样:
POST /export-tasks
HTTP/1.1 202 Accepted
Location: /tasks/task_123
{
"taskId": "task_123",
"status": "QUEUED"
}
GET /tasks/task_123
HTTP/1.1 200 OK
{
"taskId": "task_123",
"status": "SUCCESS",
"progress": 100,
"result": {
"downloadUrl": "https://example.com/report.xlsx"
}
}
这里的关键不是“换了个接口”,而是用户的等待从“卡在一个请求里”,变成了“有状态、可查询、可恢复的后台任务”。
现实中的例子
像 AI 生图、视频转码、合同解析,本质上都是同一类问题:
- 先提交任务
- 后台慢慢处理
- 前端通过轮询、SSE、WebSocket 或回调拿结果
下面这两张图就是这种交互方式的典型表现:
你在很多 AI 产品里看到的“先转圈,再逐步出现结果”,背后基本都是任务系统,而不是一个同步 HTTP 请求硬撑到底。
这一篇要记住的核心点
- Web 请求适合短平快交互,不适合把 worker 长时间占住
- 长任务不是一次请求,而是一个有生命周期的后台作业
- 真正合理的做法是:请求负责创建任务,任务系统负责执行任务
下一篇开始,就把这个“任务”进一步抽象成一个清晰的系统对象来看。