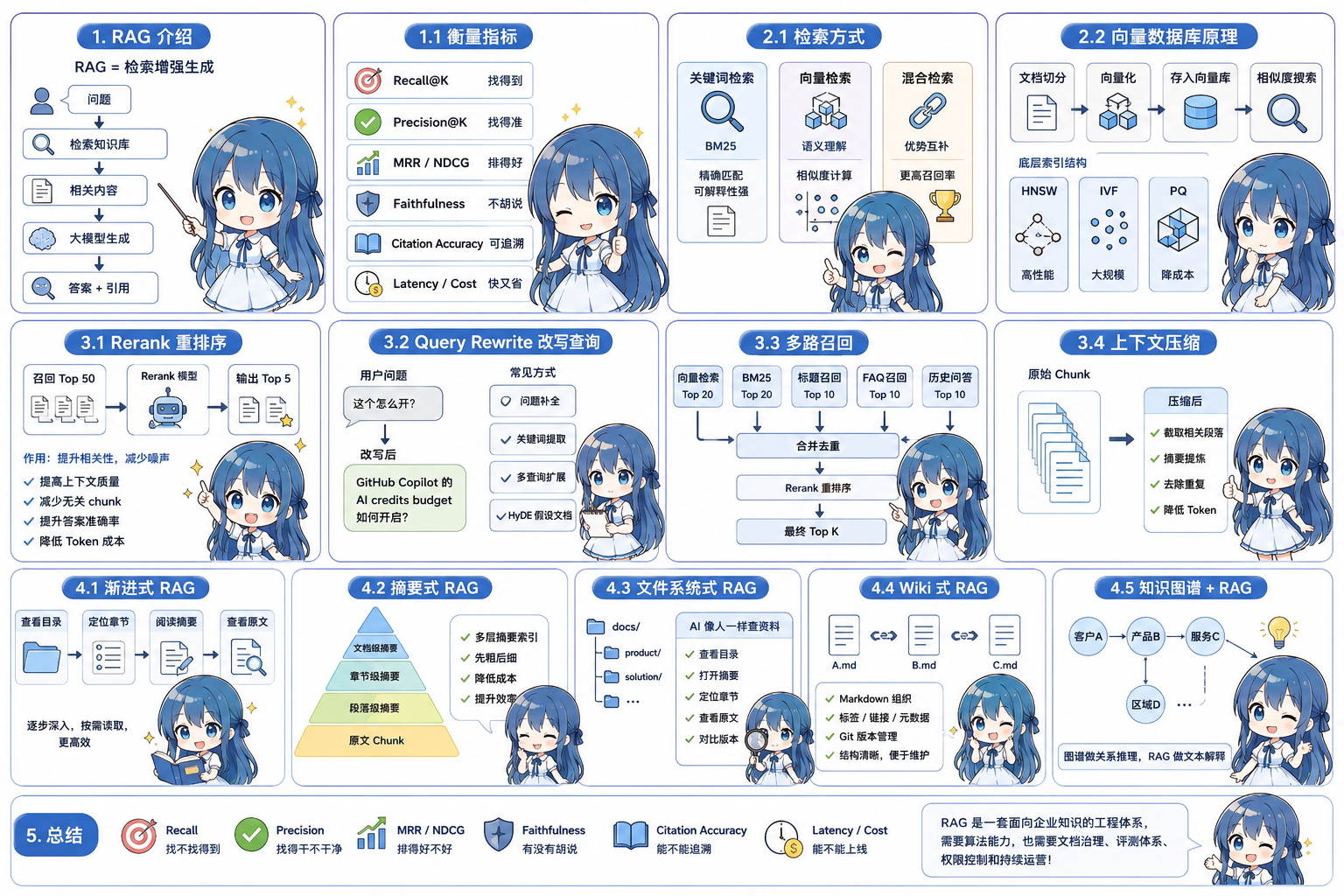
1. rag介绍
RAG,全称 Retrieval-Augmented Generation,中文一般叫“检索增强生成”。
简单理解,RAG 不是让大模型完全依赖自身参数知识回答问题,而是在回答前先从外部知识库中检索相关内容,再把检索结果作为上下文交给大模型生成答案。
它解决的核心问题是:
- 大模型知识有时效性,训练数据可能过期;
- 企业内部知识不在模型训练数据中;
- 单纯依赖模型容易产生幻觉;
- 业务场景需要答案可追溯、可引用、可审计。
所以,RAG 的本质不是“把文档上传给 AI”,而是构建一套“知识检索 + 上下文增强 + 大模型生成”的问答系统。
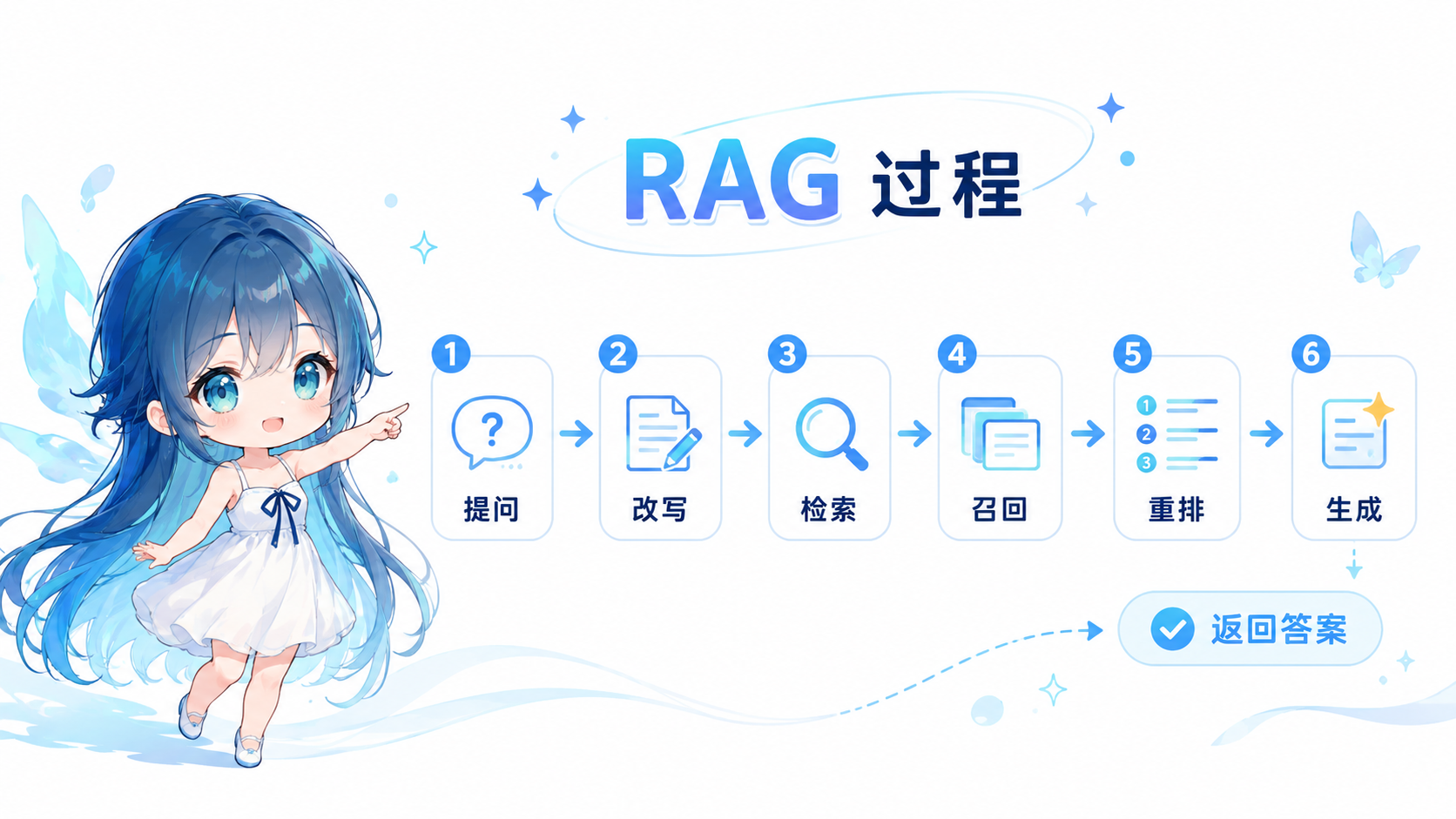
过程
一个典型 RAG 流程如下:
用户问题
↓
问题预处理 / Query Rewrite
↓
检索知识库
↓
召回相关文档片段 Chunk
↓
可选:Rerank 重排序
↓
拼接上下文 Prompt
↓
大模型生成答案
↓
返回答案与引用来源
其中比较关键的环节有三个:
第一是文档处理。原始文档通常不能直接送入知识库,需要进行解析、清洗、切分、向量化和元数据标注。
第二是检索。系统需要根据用户问题,从知识库中找到最相关的文档片段。
第三是生成。模型需要严格基于检索结果回答,而不是自由发挥。
衡量指标

RAG 系统不能只看“能不能回答”,还要看回答是否准确、稳定、可追溯。常见指标如下。
1. Recall@K:召回率
衡量前 K 条检索结果中是否包含正确内容。
Recall@K = |Relevant ∩ Retrieved@K| / |Relevant|
其中:
- Relevant:所有相关文档;
- Retrieved@K:前 K 条检索结果。
如果 Recall@K 低,说明系统没有把答案所需内容找出来,常见问题是文档切分不合理、Embedding 模型不合适、检索策略单一。
2. Precision@K:准确率
衡量前 K 条检索结果中,有多少是真正相关内容。
Precision@K = |Relevant ∩ Retrieved@K| / K
如果 Precision@K 低,说明检索出来的噪声太多,模型容易被无关内容干扰,导致答非所问。
3. MRR:平均倒数排名
衡量第一个正确结果排在第几位。
MRR = (1 / N) × Σ(1 / rank_i)
rank_i 表示第 i 个问题中第一个正确结果的排名。
MRR 越高,说明正确内容越靠前。对于 RAG 来说,正确内容排得越靠前,越容易被模型使用。
4. NDCG@K:排序质量
NDCG 用于衡量检索结果整体排序是否合理。
DCG@K = Σ(rel_i / log2(i + 1))
NDCG@K = DCG@K / IDCG@K
rel_i 表示第 i 条结果的相关性分数,IDCG 是理想排序下的 DCG。
NDCG 适合用来评估 Rerank 模型的效果。
5. Faithfulness:忠实度
衡量模型回答是否能被检索上下文支撑。
Faithfulness = 被上下文支持的陈述数 / 回答中的总陈述数
这是 RAG 中非常重要的指标,用于判断模型是否幻觉。如果答案中很多内容在知识库里找不到依据,Faithfulness 就会偏低。
6. Citation Accuracy:引用准确率
企业知识库场景通常需要答案带引用。引用准确率用于衡量引用是否真的支撑答案内容。
Citation Accuracy = 正确引用数量 / 总引用数量
引用不是为了形式上“看起来专业”,而是为了让答案可追溯、可验证。
7. Latency 和 Cost
RAG 也要关注工程指标。
Total Latency = Query Rewrite + Retrieval + Rerank + Generation
Cost = Input Tokens × 输入单价 + Output Tokens × 输出单价
RAG 成本通常主要来自输入 tokens,因为检索出来的文档片段会被拼进 prompt。如果 chunk 太多、上下文太长,延迟和成本都会上升。
2. 传统rag检索
传统 RAG 的核心是:用户提出问题后,系统从知识库中找出相关文档片段,再交给大模型回答。
在这个阶段,重点通常是文档切分、Embedding、向量检索、关键词检索和检索参数调优。
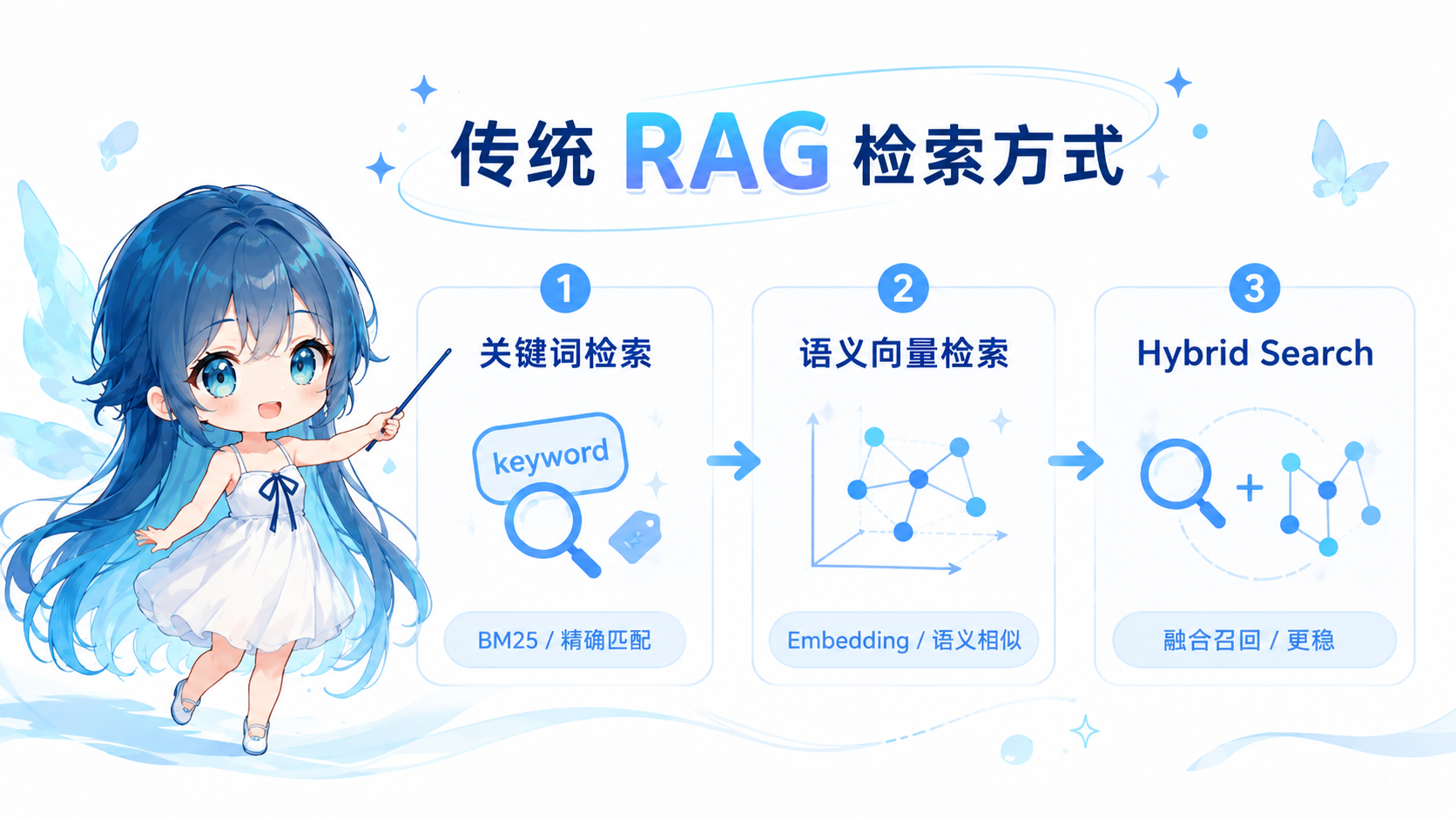
检索方式
1. 关键词检索
关键词检索主要依赖文本中的词频、关键词匹配和倒排索引。
Elasticsearch / OpenSearch 中常见的 BM25 算法就可以实现关键词检索。
BM25 可以简单理解为:如果一个文档中频繁出现用户查询的关键词,并且这些关键词不是所有文档中都常见的普通词,那么这个文档就更可能相关。
BM25 的优势:
- 对精确关键词、编号、产品型号、错误码很友好;
- 可解释性强;
- 工程成熟,性能稳定。
不足:
- 不理解语义;
- 对同义词、口语化表达支持较弱;
- 用户问题和文档表达不一致时,容易漏召回。
例如用户问“怎么重置密码”,文档里写的是“账户凭据初始化”,纯关键词检索可能就不容易命中。
2. 语义向量检索
语义向量检索会先把文本转换成向量,也就是 Embedding。
Embedding 可以理解为一组数字,用来表示文本的语义特征。语义相近的文本,在向量空间中的距离也更近。
基本流程是:
文档切分
↓
Chunk 向量化
↓
存入向量数据库
↓
用户问题向量化
↓
计算相似度
↓
返回最相似的 Chunk
常见相似度计算方式有:
Cosine Similarity = A · B / (||A|| × ||B||)
语义向量检索的优势:
- 能理解一定程度的语义相似;
- 对自然语言问题更友好;
- 适合知识问答、FAQ、文档助手等场景。
不足:
- 对精确关键词不一定敏感;
- 依赖 Embedding 模型质量;
- 对长文档、表格、代码、编号类内容效果不稳定;
- 向量相似不等于业务相关。
3. Hybrid Search 混合检索
Hybrid Search 是关键词检索和向量检索的结合。
常见方式是:
BM25 召回一批结果
向量检索召回一批结果
合并结果
去重
重新排序
返回给大模型
混合检索的好处是同时兼顾:
- 关键词检索的精确匹配能力;
- 向量检索的语义理解能力。
例如:
- 查询错误码、产品型号、接口名时,BM25 通常更准;
- 查询概念解释、业务问题、自然语言问题时,向量检索更有优势;
- 两者结合后,整体 Recall 通常更稳定。
在企业 RAG 中,Hybrid Search 往往比单纯向量检索更可靠。
向量数据库的介绍
向量数据库用于存储和检索 Embedding 向量。
普通数据库擅长结构化查询,例如:
select * from table where id = 1;
而向量数据库擅长相似度查询,例如:
找到和这个问题语义最相近的 10 个文档片段
常见向量数据库或向量检索组件包括:
- Milvus
- Qdrant
- Weaviate
- pgvector
- Elasticsearch Vector Search
- OpenSearch Vector Engine
- FAISS
向量数据库通常会保存两类信息:
- 向量本身;
- 文档内容和元数据。
元数据非常重要,例如:
文档名称
章节标题
页码
更新时间
权限范围
产品类型
语言
部门
有了元数据后,可以做过滤检索。例如只检索“某个产品线”“某个部门”“最近一年”的文档。
底层原理介绍
向量检索本质是最近邻搜索,也就是找到距离用户问题向量最近的一批文档向量。
如果数据量很小,可以直接暴力计算所有向量之间的相似度。但当文档量达到百万级、千万级时,暴力计算成本会很高。
所以向量数据库通常使用 ANN,也就是 Approximate Nearest Neighbor,近似最近邻搜索。
它的目标不是每次都 100% 找到数学意义上最精确的最近邻,而是在速度和准确率之间做平衡。
常见索引结构包括:
1. HNSW
HNSW 可以理解为一个多层图结构。
底层连接大量节点,越往上节点越少。搜索时先从上层快速定位大概区域,再逐层向下精细查找。
优势:
- 查询速度快;
- 召回效果好;
- 适合在线检索。
不足:
- 内存占用较高;
- 构建索引成本较高。
2. IVF
IVF 可以理解为先把向量分成多个簇。
查询时,不再扫描所有向量,而是先找到最可能相关的几个簇,再在这些簇中搜索。
优势:
- 适合大规模向量;
- 查询效率高。
不足:
- 需要训练聚类中心;
- 参数设置会影响召回效果。
3. PQ
PQ 是 Product Quantization,乘积量化。
它的核心思想是压缩向量,减少存储和计算成本。
优势:
- 降低存储成本;
- 适合超大规模数据。
不足:
- 会牺牲一定精度;
- 对召回率有影响。
简单来说:
HNSW:更偏高性能在线检索
IVF:更偏大规模分桶检索
PQ:更偏压缩降成本
3. 进阶 RAG 检索
传统 RAG 的问题是:检索出来的内容不一定真的适合回答问题。
所以进阶 RAG 通常会在检索链路中加入更多处理,例如 Rerank、Query Rewrite、多路召回、上下文压缩、元数据过滤等。
1. 引入 Rerank 模型进行重排序
Rerank 的作用是对初步召回的结果重新排序。
一般流程是:
Retriever 先召回 Top 50
↓
Reranker 对问题和每个 Chunk 重新打分
↓
选出 Top 5 或 Top 10
↓
交给大模型生成答案
Retriever 通常负责“快速找一批可能相关的结果”,Reranker 负责“更精细地判断哪些结果真正相关”。
为什么需要 Rerank?
因为向量检索通常只比较向量距离,但向量距离相近不代表一定能回答问题。Reranker 会同时看“问题”和“文档片段”的语义关系,判断这个片段是否真的能支撑答案。
Rerank 的优势:
- 提高上下文质量;
- 减少无关 chunk;
- 提升答案准确率;
- 降低模型输入 token 成本。
Rerank 的代价:
- 增加额外模型调用;
- 增加延迟;
- 并发高时需要考虑推理成本。
一般经验是:先召回较多结果,再用 Rerank 精排少量结果。例如召回 Top 30,再重排取 Top 5。
2. 前置改写查询语句 Q,提高知识库命中率
用户的问题往往不是标准检索语句,可能存在口语化、缩写、上下文省略、多意图混合等情况。
例如用户问:
这个怎么开?
如果没有上下文,系统很难知道“这个”是什么。
Query Rewrite 的作用就是把用户问题改写成更适合检索的查询语句。
常见方式包括:
1. 问题补全
根据上下文补全省略信息。
原问题:这个怎么开?
改写后:GitHub Copilot 的 AI credits budget 如何开启?
2. 关键词提取
从自然语言问题中提取核心检索词。
原问题:为什么我的 Azure 模型部署老是 429?
关键词:Azure OpenAI, 429, quota, rate limit, TPM, RPM
3. 多查询扩展
把一个问题扩展成多个检索查询。
用户问题:RAG 如何降低幻觉?
扩展查询:
1. RAG 幻觉原因
2. RAG faithfulness 指标
3. RAG 引用校验
4. RAG grounded answer
4. HyDE
HyDE 是 Hypothetical Document Embeddings。
它的思路是:先让模型根据问题生成一个“假设答案”或“假设文档”,再对这个假设文档做向量检索。
适合用户问题很短、表达不清晰,但大概意图可判断的场景。
不过 HyDE 也有风险。如果假设答案本身偏了,检索方向也会偏。
3. 多路召回
进阶 RAG 中常见做法不是只用一个检索器,而是多路召回。
例如:
向量检索召回 Top 20
BM25 召回 Top 20
标题字段召回 Top 10
FAQ 问题召回 Top 10
历史问答召回 Top 10
然后合并、去重、重排序。
多路召回的好处是提高 Recall,减少漏召回。尤其在企业知识库中,文档类型复杂,单一检索方式很难覆盖所有问题。
4. 上下文压缩
检索出来的 chunk 不一定都要完整塞给大模型。
上下文压缩的目标是:保留能回答问题的关键信息,去掉无关内容。
常见方式:
- 只截取命中句子附近内容;
- 对长 chunk 做摘要;
- 提取和问题相关的段落;
- 删除重复内容;
- 根据标题层级保留结构化上下文。
这可以降低 token 成本,也能减少模型被噪声干扰。
4. 未来 RAG 形式
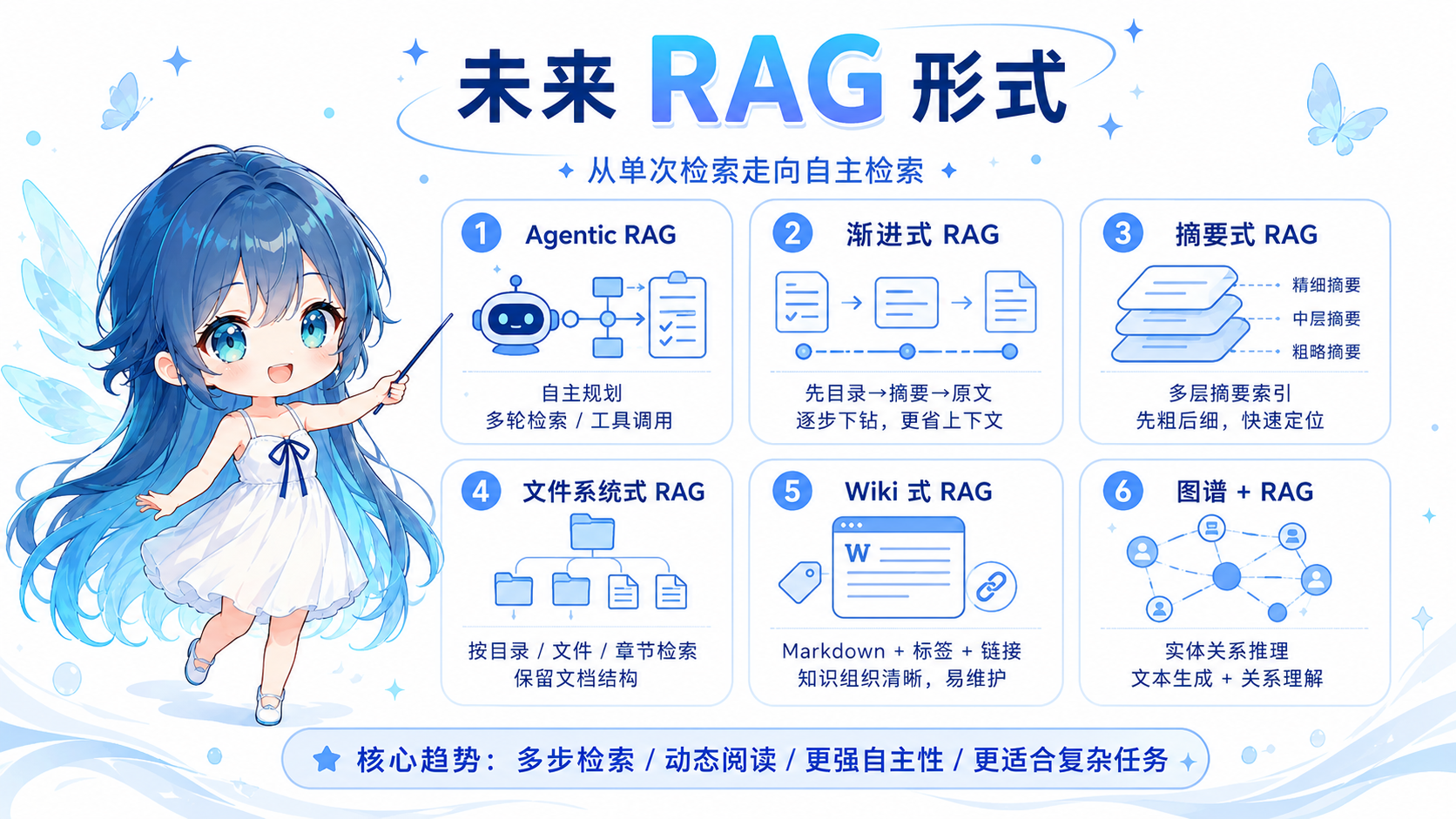
RAG 不会消失,但会从“单次检索 + 单次回答”逐渐演进为“智能体式检索 + 多步推理 + 动态读取资料”。
2026 年后进入 Agent 时代,给 AI 更多自主权,会显著提高复杂任务的处理效果。
传统 RAG 通常是:
问一次
检索一次
回答一次
Agentic RAG 更像是:
理解任务
规划检索步骤
多次检索
阅读摘要
必要时查看原文
对比多个来源
生成答案
校验引用
也就是说,系统不再只是被动检索,而是让 AI 自己判断需要查什么、查几次、是否继续深入。
1. 渐进式 RAG
渐进式 RAG 指的是 AI 不一次性把所有内容塞进上下文,而是逐步检索、逐步阅读。
例如:
先检索目录
再定位章节
再读取摘要
最后查看原文细节
这种方式更适合长文档、多文档、复杂问题。
优势:
- 避免上下文过长;
- 降低 token 成本;
- 更接近人类查资料的过程;
- 适合复杂分析任务。
2. 摘要式 RAG
摘要式 RAG 会提前对文档生成多层摘要。
例如:
文档级摘要
章节级摘要
段落级摘要
原文 Chunk
用户问题进来后,系统可以先从高层摘要判断方向,再逐步下钻到具体原文。
这种方式适合企业知识库、项目文档、技术方案、会议纪要等场景。
它的核心不是只存原文,而是建立“摘要索引 + 原文索引”的多层知识结构。
3. 文件系统式 RAG
未来复杂知识库可能更像文件系统,而不是简单的向量库。
AI 可以像人一样:
查看目录
读取文件名
打开摘要
定位章节
查看原文
对比版本
引用来源
这种方式更适合大型企业文档库,因为企业知识往往有明显结构,例如部门、项目、产品、版本、时间、权限等。
文件系统式 RAG 的关键是保留文档结构,而不是把所有内容切成互相独立的 chunk。
4. Wiki 式 RAG
Wiki 式 RAG 是一种更适合长期维护的知识组织方式。
它通常以 Markdown 文档为主要载体,通过目录、链接、标签、元数据和引用关系组织知识。
例如:
docs/
products/
copilot.md
azure-openai.md
solutions/
rag-solution.md
agent-solution.md
cases/
customer-a.md
customer-b.md
每个 Markdown 文档可以包含 front matter:
title: Azure OpenAI 配额说明
tags:
- azure
- openai
- quota
updated: 2026-06-11
owner: cloud-team
Wiki 式 RAG 的优势:
- 文档结构清晰;
- 方便人工维护;
- 适合和 Git 结合做版本管理;
- 适合生成目录、摘要和知识图谱;
- 对 Agent 检索非常友好。
在 Agent 后时代,RAG 可能不再只是“向量数据库问答”,而是变成“AI 可读的知识工程系统”。
5. 知识图谱 + RAG
对于关系复杂的场景,可以在 RAG 中引入知识图谱。
向量检索擅长找语义相似内容,但不擅长表达强关系,例如:
A 产品属于哪个系列
某个客户购买了哪些服务
某个合同关联哪些项目
某个故障由哪些组件引起
知识图谱可以把实体和关系显式表达出来。
例如:
客户 A → 购买 → 产品 B
产品 B → 依赖 → 服务 C
服务 C → 部署在 → Azure 区域 D
图谱适合做关系推理,RAG 适合做文本解释。两者结合后,可以同时获得结构化推理能力和自然语言生成能力。
5. 总结
RAG 的核心不是简单地把文档放进知识库,而是围绕“检索质量、上下文质量、生成质量、工程性能”持续优化。
可以简单记住:
Recall 解决:找不找得到
Precision 解决:找得干不干净
MRR / NDCG 解决:排得好不好
Faithfulness 解决:有没有胡说
Citation Accuracy 解决:能不能追溯
Latency / Cost 解决:能不能上线
传统 RAG 更关注检索和生成,进阶 RAG 会引入 Rerank、Query Rewrite、多路召回和上下文压缩。
未来 RAG 会进一步向 Agentic RAG、渐进式 RAG、摘要式 RAG、文件系统式 RAG 和 Wiki 式 RAG 演进。
最终,RAG 不只是一个技术组件,而是一套面向企业知识的工程体系。它既需要算法能力,也需要文档治理、评测体系、权限控制和持续运营。